표준이 된 세벌식? - (2) 마구 꼬여 가는 표준 한글 부호계
1) KS 완성형 한글 부호계의 황당한 모순
1987년에 공업진흥청은 행정 전산망(행망)에 쓰려고 만든 문자 부호계를 KS C 5601(정보 교환용 부호계, 지금의 KS X 1001)에 올려 표준 규격으로 삼았다. 흔히 KS 완성형으로 불리는 이 부호계에는 국제 규격인 ISO 2022의 부호계 확장법에 따라 2바이트 부호값들에 한글 낱내 완성자 2350개와 한자 4888자를 비롯한 8224개 문자들이 담겨 있다.(그림 11-1)주1 KS 완성형 부호계는 국내 표준 부호계로서 여러 한글 지원 프로그램들과 PC 통신망들에서 널리 쓰이는 문자 부호계로 자리잡았다.

한글 낱내 완성자 2350개가 들어간 KS 완성형 부호계는 널리 쓰이면서 큰 모순이 드러났다. 요즘한글에 쓰이는 첫소리 낱자 19개, 가운뎃소리 낱자 21개, 끝소리 낱자 27개로 조합할 수 있는 낱내 완성자는 11172개인데, KS 완성형 부호계에 들어간 한글 완성자 2350개로는 외국어는커녕 우리말을 나타내기에도 모자랐다. 사투리인 '똠방'과 '됭기다'의 '똠'과 '됭'을 적을 수 없었고, 표준어인 '하얬다'와 '설렜다'와 '전홥니다'의 '얬'과 '렜'과 '홥'을 적을 수 없었다. 상표인 '펲시콜라'는 '펲'을 적을 수 없어서 '펩시콜라'로 바꾸어 했고, '믜'를 KS 완성형을 쓰는 전산망에 올릴 수 없어서 이름이 '설믜'인 사람들이 수난을 겪어야 했다.주2


한글 완성자 2350개가 들어간 KS 완성형 부호계에는 '쓩'은 있지만 '쓔'는 없다. 그래서 KS 완성형을 쓰는 프로그램에서는 한글 자판으로 '쓩'을 치면 ㅆㅠㅇ으로 풀려 나왔다. '쓩'은 문자표에서 복사하거나 부호값을 쳐서 넣을 수 있지만, 한글 자판으로 넣을 수는 없었다. 이 문제를 이야기한 월간 《마이크로소프트웨어》도 '쓔'와 '쓩'을 나타내는 일에 어려움을 겪었다. 종이 잡지에는 '쓔'와 '쓩'이 나오지만,주3 이를 전자 매체인 CD로 옮긴 전자 잡지 '마이크로소프트웨어 CD issue'(그림 11-3)에는 KS 완성형에 부호값이 없는 '쓔'가 '...99'으로 나온다. '똠'은 전자 잡지에서 문자가 아닌 그림으로 처리되었다.
'쓩'과 비슷한 예로 비슷한 예로 뢨, 썅, 쏀, 쭁이 있다. 이들도 KS 완성형 부호계에 올라 있지만 뢔, 쌰, 쎼, 쬬가 없어서 글쇠를 눌러 넣지 못한다.주4 주5


《마이크로소프트웨어》 1998년 11월호에 실린 「민족 문화의 정수, 한글을 한글답게! ― 펩시맨과 똠방각하가 찦차를 탄 이유는…」(전상훈)에서도 그림 11-4 ~ 11-5과 비슷한 문제가 나타나 있다. 종이로 인쇄된 잡지 원본(그림 11-4)에는 '펲시맨'과 '똠방각하' 등이 비트맵 글꼴로 찍혀 있는데, 종이 잡지를 파일로 옮긴 PDF판(그림 11-5)에는 이들이 한글 부호값이 빠진 채로 흐릿한 그림으로 들어갔다. KS 완성형으로 나타내지 못하는 글을 임시 방편으로 그림으로 넣었다가 다른 매체로 옮겼을 때에 나타날 수 있는 모습이다.
전산 부호값으로 '똠', '펲'을 자유롭게 나타내지 못한 때는 그리 길지 않았다. 하지만 그 기간 동안에 제대로 적지 못한 '똠', '펲' 같은 말들을 빠뜨리지 않고 기록으로 남기려면 아직도 많은 공을 들여야 할 수 있다.
KS 완성형으로 '쓔'와 같은 낱내자를 나타낼 방안이 전혀 없었던 것은 아니다. KS 완성형 부호계를 담은 KS C 5601에서는 두벌식 낱자들을 이어 붙여서 2350자에 들어가지 못한 한글 낱내 완성자를 나타낼 길을 열어 두었다.
- 아 → 채움 + ㅇ + ㅏ
- 괞 → 채움 + ㄱ + ㅙ + ㄶ
- 갂 → 채움 + ㄱ + ㅏ + ㄲ
이 표현 방식은 앞의 글에서 살핀 3바이트 조합형을 바탕으로 하면서, 채움 부호(fill code)를 낱내자의 시작 부호로 앞세우는 규칙을 덧붙인 것이다. 그런데 이 표현 방식은 표준을 설명한 문서에 예시만 되었고, 부호값과 글꼴을 처리하여 글을 나타낼 구체 방안이 나오지 않아서 실제로 쓰인 사례는 없었다.
표준어(전홥니다), 사투리(똠방), 사람 이름(설믜), 상표(펲시)를 나타내지 못하기도 하는 KS 완성형 부호계는 자꾸 이상한 사건들을 자꾸 일으켰다. 수동 타자기나 구형 8비트 컴퓨터를 쓰던 때에도 겪어 보지 못한 어처구니 없는 일들을 때때로 일으키는 바람에 KS 완성형 부호계는 사람들의 비웃음을 사며 KS 규격의 권위를 땅에 떨어뜨렸다. 전산 환경에 쓰이는 문자 부호계는 프로그램 개발자나 관련 분야 연구자가 아니면 관심을 기울이는 사람이 많기 어렵지만, KS 완성형이 말글살이에 미치는 사건들은 한글 전산화에 관심이 없던 사람들에게도 깊은 인상을 남길 만큼 상식밖이었다.
4년마다 한번씩 온 세계를 떠들썩하게 만드는 월드컵 축구의 열기는 우리나라에도 예외는 아니어서 대회 기간동안 신문을 펼쳐도 텔레비전을 켜도 온통 그 보도 뿐이다. 아마 축구를 좋아하지 않더라도 지난해에 열린 로마 월드컵에 출전한 선수 이름 몇몇 정도는 아직도 기억하는 사람이 많을 것이다.
로마 월드컵 출전 선수 가운데 컴퓨터 관계자들 사이에서 유명한 선수로 독일의 푈러가 있다. 이 선수가 컴퓨터를 잘 만지는 사람도 아니고 마라도나 같은 불세출의 스타도 아닌데 이런 영광을 누르는 이유는 순전히 부모를 잘 만난 덕이라고 볼 수 있다. 이름에 들어 있는 ‘푈’자가 이 선수를 컴퓨터계의 스타로 만든 것이다.
아이러니컬하게도 이 글자는 KS규격을 따내지 못하는 불량품이다. 글자에도 KS가 있느냐고 놀라는 독자가 있을 것이다. 볼펜 한자루에도 여러가지 KS규격이 적용되는데, 하물며 더 복잡한 컴퓨터분야에 KS규격이 없을 리가 없다. 이 가운데 하나가 컴퓨터에서 쓰이는 한글 코드에 대한 규격을 정해 놓은 것으로, 여기에 따르면 컴퓨터에서는 지정된 한글 2천3백50자만 사용하도록 되어 있다. 이 2천3백50자에 ‘푈’자는 포함되어 있지 않으니 이 글자는 써서는 안되는 불량품인 것이다.
신문사나 인쇄소의 전산사식기도 이 KS규격에 맞춘 것이므로 ‘푈’자에 대해서는 무방비 상태였는데 난데없이 이상한 이름을 가진 독일 사람이 나타나 비상이 걸렸고, ‘푈’자만 적당히 손으로 만들어 끼워 넣는 해프닝이 벌어졌다. 속사정을 아는 사람들은 말쑥한 글자들 사이에서 유독 그 글자만 모양이 이상한 이유를 알고 있으니, 신문을 볼 때마다 ‘푈러 푈러’ 외우지 않을 수가 없었다.
정내권, 「KS 한글 코드 바뀌어야 한다 - 한글 문화에 적합한 「조합형」으로」, 《과학동아》 1991.10.
▣ KS 완성형 한글 부호계가 쓰인 '한글 윈도우 3.1'

한글판으로 나온 윈도우 3.1의 문서작성기(요즈음 판의 '워드패드')에서는 커서가 조합하고 있는 한글 낱내의 앞쪽에 있는 것만 다를 뿐, 오늘날에 쓰이는 것과 같은 한글 조합 방식이 쓰였다. 하지만 낱내 완성자를 2350자로 제한한 KS 완성형 부호계를 썼기 때문에 '똠'을 넣으면 '또ㅁ'으로 풀려 나오는 문제가 있었다. KS 완성형 부호계에 '갃'이 없기 때문에 두벌식 자판으로 '각시'를 넣을 때에 '갃'이 도깨비불로 나타나지 않는다.
아래는 "똠방, 됭기다, 설렜다, 하얬다, 어씃, 설믜, 쓩, 찦차, 쑛다리, 펲시"를 넣었을 때에 "또ㅁ방, 되ㅇ기다, 설레ㅆ다, 하얘ㅆ다, 어쓰ㅅ, 설므ㅣ, 찌ㅍ차, 쑈ㅅ다리, 페ㅍ시"로 풀려 나오는 모습이다.
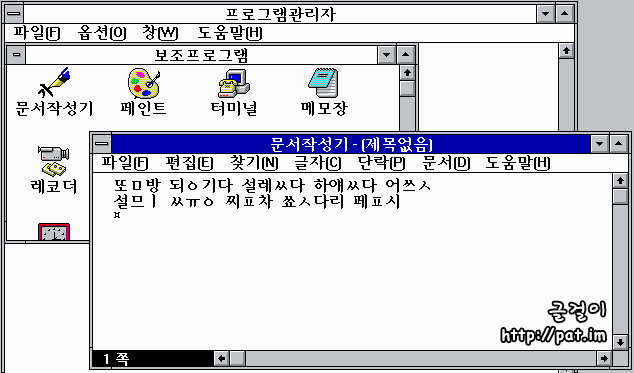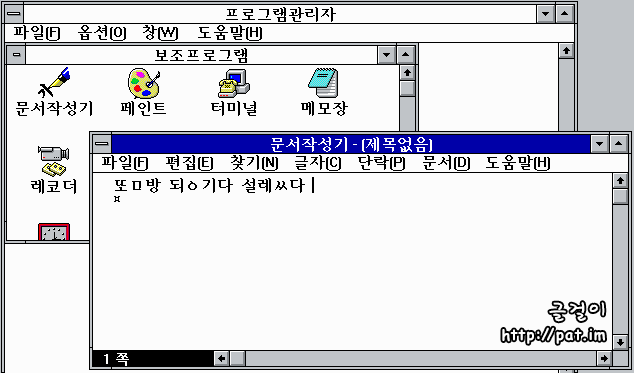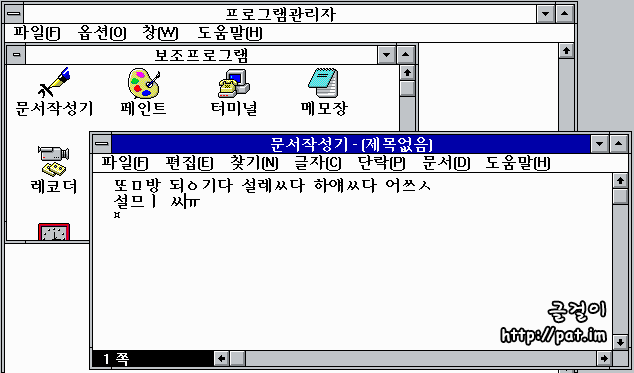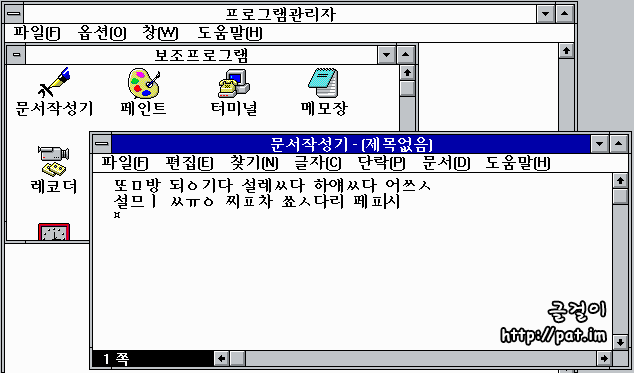
이처럼 똠, 됭, 렜, 얬, 씃, 믜, 쓩, 찦, 솟, 펲을 나타내지 못하는 것은 이 무렵에 쓰인 프로그램들의 한글 처리 기술이 모자랐기 때문이 아니라 1987년에 제정된 KS 완성형 한글 부호계의 모순 때문이었다. 이는 한글 윈도우 3.1만이 아니라 KS 완성형 한글 부호계를 쓰는 프로그램들이 공통으로 겪던 문제였다.
2) 표준화는 이루었으나 온전한 대안은 되지 못한 2바이트 조합형
KS 완성형과 달리 2바이트 조합형은 얬 · 똠 · 됭 · 펲 같은 낱내자들을 모두 나타낼 수 있다. 2바이트 조합형 부호계에서는 첫소리 19개, 가운뎃소리 21개, 끝소리 29개로 조합할 수 있는 한글 낱내 완성자 11172개를 나타낼 수 있고, 'ᅟᅳᆫ'이나 'ᄀᅠᆨ'처럼 처럼 첫소리 · 가운뎃소리 낱자가 빠진 미완성 한글 낱내도 넣을 수 있다. 한글 낱자 분석이 쉬운 점 때문에 프로그램 개발자들은 2바이트 완성형보다 2바이트 조합형을 더 편하게 느낄 수 있었다. 2바이트 조합형은 KS 완성형보다 한글 조합폭이 넓은 것 때문에 일반 사용자들과 전문 프로그램 개발자들의 지지를 얻었다. 그래서 민간 시장의 수요에 맞춘 한글 입출력 프로그램들은 표준인 KS 완성형을 공통으로 지원하면서 2바이트 조합형도 함께 지원하는 때가 흔했다.
1990년대에 들어서는 2바이트 조합형 부호계의 종류가 많은 것이 큰 흠은 아니게 되었다. 1980년대에 금성 조합형, 삼성 조합형, 상용 조합형 등으로 나뉘었던 2바이트 조합형이 1990년대에 상용 조합형으로 거의 통일되었기 때문이다. 그러나 한글을 나타내는 부호값의 수가 12000개를 넘는 것 때문에 제어 부호를 피하는 문제는 완벽히 풀 수 없었다.
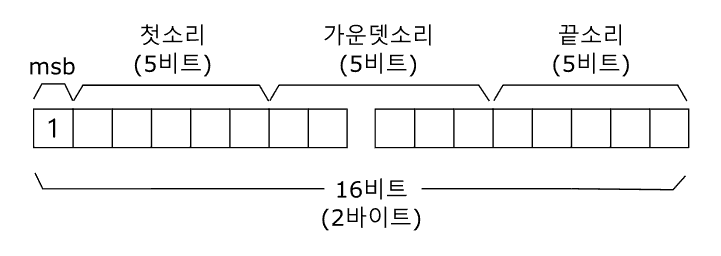
1990년대 중반까지의 동아시아 컴퓨터 환경에서는 ISO 2022에 바탕한 부호계 확장법이 많이 쓰였다. 그림 11-9처럼 이 부호계 확장법을 따른다면 문자를 나타내는 맨 첫째 비트(최상위 비트, msb)의 값이 0이면 1바이트(8비트) 부호값으로 7비트 아스키(ASCII) 영역의 문자들을 나타내고, 맨 첫째 비트가 1이면 바로 뒤의 바이트까지 묶어 2바이트(16비트)로 아스키 영역 밖의 문자들을 나타낸다. 영문 자판에 들어가는 영문자 · 숫자 · 기호는 1바이트로 나타내었고, 한글 및 한자와 전각 기호들은 대체로 2바이트로 나타내었다.
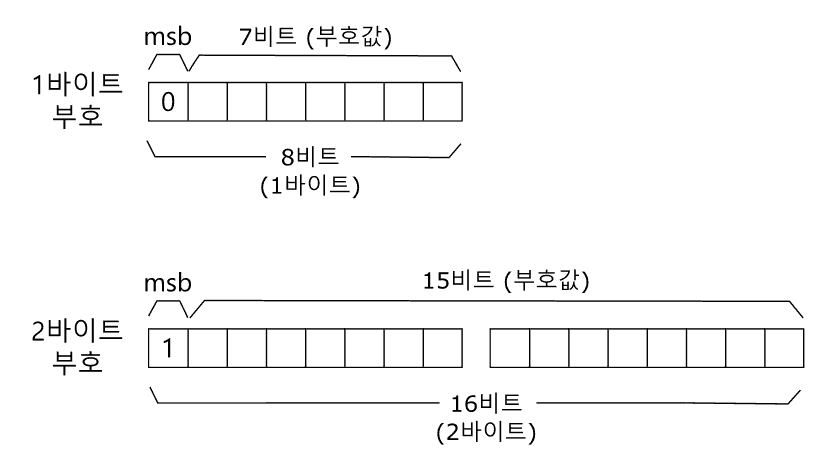
이 부호계 확장법은 2바이트 문자 처리를 완벽하게 하지 못할 때에 문제가 생길 수 있다. 2바이트로 나타내는 문자를 1바이트씩 끊어 읽으면, 운영체제나 응용 프로그램에 쓰이는 메타 문자들([, ], &, %, ~, ^, *, \, | 따위)나 통신망에서 쓰이는 제어 부호로 잘못 받아들여질 수 있기 때문이다. 메타 문자나 제어 부호로 잘못 받아들여지는 때에는 글이 깨져 나오는 것에 그치지 않고 프로그램이 잘못된 동작을 하는 원인이 될 수도 있다. 이론을 따지면 ISO 2022을 따르는 부호계 확장법으로 2바이트 부호값을 32768개(2¹⁵개)까지 둘 수 있지만, 프로그램이나 통신망이 제어 신호로 받아들일 수 있는 부호값을 피한다면 마음 놓고 쓸 수 있는 부호값은 32768개보다 적을 수밖에 없었다.
한글 완성자를 2350개만 넣은 KS 완성형 부호계는 두째 바이트의 첫 비트가 0인 부호값을 한글을 나타내는 데에 쓰지 않는 방법으로 한글 부호값이 메타 문자나 제어 부호로 잘못 읽힐 가능성을 미리 없앴다. 하지만 2바이트 조합형은 한글 완성자 11172개를 나타내는 일에 걸려 메타 문자와 제어 부호로 읽힐 가능성을 모두 피할 방법은 없었다.ISO 2022을 따르는 부호계 확장법으로 쓸 수 있는 2바이트 부호값들의 수를 제약 조건을 붙여 셈해 보면 다음과 같다.
- 아무런 제약이 없을 때
: 128×256 = 32768 - 두째 바이트의 첫 비트가 0인 부호값을 쓰지 않음
: 128×(256-128) = 128² = 16384 - 제어 부호나 기능 문자로 읽힐 수 있는 부호값도 피함
: (128-34)² = 94² = 8836
이 때문에 2바이트 조합형은 통신 환경에서 쓰기에 알맞지 않다는 생각이 통념처럼 퍼지기도 했지만, 이 생각이 꼭 옳지는 않았다. 한글 부호값과 얽혀 문제를 일으키는 통신 제어 부호의 수는 통신망 운영 방식에 따라 달라질 수 있었다. 메타 문자와 제어 부호 가운데 우선하여 피할 요소를 고르고 통신망에서 문제가 되는 부호값을 줄여 나간다면, 2바이트 조합형 부호계를 통신망에서 쓰는 길이 없지는 않았다. 한글 처리를 전혀 헤아리지 않는 국외 호스트 환경에서는 KS 완성형을 쓰더라도 한글 부호값이 통신 제어 부호와 부딪칠 수 있었고, 통신 프로그램 개발자와 통신망 운영자가 한글 처리를 잘 헤아리는 때에는 2바이트 조합형 부호계로도 통신망을 운영할 수 있었다.
사설 통신망(사설 BBS) 가운데는 2바이트 조합형 가운데 가장 널리 쓰인 '상용 조합형'을 쓰는 곳이 있었고, 여러 저자들과의 연락과 교류가 잦은 출판업계에서는 일찍부터 조합형 한글 부호계를 통신에 썼다고 한다.
예전에는 사용자의 컴퓨터가 어떤 한글을 지원하느냐에 따라 통신용 소프트웨어를 선택해야 했다. 하지만 요즘 나오고 있는 통신용 소프트웨어들은 조합형과 완성형을 모두 지원하고 있어 한글 문제에 관해서는 별다른 고민없이 선택할 수 있다.
그러나 막상 통신용 소프트웨어를 사용해 보면 별 이상이 없는 것 같은데도 화면에는 알 수 없는 문자들이 나올 때가 있다. 이는 통신용 소프트웨어에서 한글을 잘못 설정했을 때 생기는 문제로, 케텔, PC-Serve 등 국내의 대표적인 대규모 통신 서비스는 모두 완성형 한글을 채택하고 있다.
그러나 사설 BBS 중에는 7비트 완성형 한글이나 상용 조합형 한글을 사용하고 있는 곳도 있으므로 접속하고자 하는 BBS가 사용하는 한글에 맞춰 통신용 소프트웨어의 한글을 설정하도록 한다.
「PC 통신 - 통신용 소프트웨어와 BBS 접속」, 《마이컴》 1992.4. (153~155째 쪽)
정보교환용 한글 코드는 통신 코드라고도 한다. 국제 통신 선로는 프로토콜 때문에 조합형 한글 통신이 불가능하여 2,350자 완성형 한글 코드를 한국 표준코드(KSC-5601-87)로 지정하였다는 완성형 코드 지지자들의 주장이 틀렸다는 것을 보여 주기 위하여, 1989년 7월 11일에 호주 시드니로 건너가 랩톱 컴퓨터에서 조합형 한글 코드를 사용하여 국제 전화선으로 시드니에서 서울과 한글 컴퓨터 국제 통신을 최초로 성공했다.주6 호주 시드니에서 한국서 가져간 랩톱 컴퓨터에다 전영욱 씨가 개발한 조합형 한글(CKP) 을 셜치하고, 묵현상 씨가 개발한 통신에뮬레이터 (SREVOLT) 를 설치하고 국제 전화선을 통하여 서울에 있는 (주)한국데이컴의 3B20컴퓨터를 매개로 하여 서울의 유경희 씨의 개인용 컴퓨터와 교신을 한 것이 성공한 것이다.
랩톱 컴퓨터와 개인용 컴퓨터에서 사용한 한글은 도스용 2바이트 한글 코드였고, 3B20컴퓨터는 유닉스용 N바이트 한글 코드를 사용했다. 당시 국내의 상황은, 1만 1,172자의 모든 한글올 필요로 하는 저자, 출판사 중에서, 특히, 가정 교과서, 지리 교과서, 사회과부도 둥 공동 저자가 많은 교과서의 전문 출판사나 필자가 많은 잡지 출판사, 컴퓨터 서적 전문 출판사 둥에서 먼저, 업무에 조합형 한글 컴퓨터 통신을 이용하기 시작하고 있었다.
[그림 9] 한글 컴퓨터 통신을 최초로 사용한 출판사
----------------------------------------------------------------------
(주)장왕사 1982년부터 삼민사 1984년-1989년 월간디자인 1986년부터 영진출판사 1987년부터 ----------------------------------------------------------------------
이기성, 「전자공학의 관점에서 본 컴퓨터와 한글」, 《새국어생활》 제6권 제2호, 1996.6.29.
상용 조합형은 1980년대 초반에 한국 IBM에서 쓰기 시작하여 삼보, 큐닉스, 대우, 현대를 비롯한 많은 업체들의 지지를 얻은 2바이트 조합형 한글 부호계이다. 삼보컴퓨터가 주도하여 만들었다고 하여 '삼보 조합형'으로도 불리었고, 1992년에 KS C 5601의 보조 부호계로 들어간 뒤에는 KSSM으로 흔히 불리었다.
상용 조합형은 2바이트 한글 정보를 1바이트씩 나누어 읽더라도 프로그램에 쓰이는 메타 문자로 읽히는 것을 최소한으로 줄이는 것에 집중한 것이 특징이다.주7 프로그램마다 한자와 기호 구성을 조금씩 달리했지만, 상용 조합형은 여러 업체들의 지지를 받으며 2바이트 조합형 한글 부호계 가운데 업계에서 가장 굳건하게 자리를 다져 나갔다. ᄒᆞᆫ글에서 쓰인 옛낱자를 더 넣은 '한컴 2바이트 조합형'도 상용 조합형의 범주에 들어간다.
KS 완성형 부호계가 표준이 된 명분은 국제 규격(ISO 2022 등)을 따르는 통신 환경에서 한글 정보를 주고받을 때에 걸리는 문제가 가장 적은 것에 있었다. 그러나 KS 완성형 부호계가 국제 통신 규격에 가장 맞다는 것이 다른 나라의 통신망에서 한글 정보를 바로 주고받을 수 있음을 뜻하지는 않았다. 7비트 아스키 영역만 세계 공통으로 쓰일 뿐, 거기에 더하여 쓰는 문자 부호계는 문화권마다 부호계 확장 방법과 문자 구성이 달랐기 때문이다. 그래서 한글 정보를 주고받는 사람들에게는 KS 완성형의 좋은 점이 와닿기 어려웠고, '똠'이나 '펲' 같은 낱내자들을 나타내지 못하는 것이 더 크게 와닿을 수 있었다.
컴퓨터를 쓰는 사람이 늘수록 두벌식이나 세벌식을 따지는 한글 자판 논쟁은 상대적으로 관심이 사그라들었다. 일반 사용자의 입장에서 보면 전산 환경에서 널리 쓰이는 한글 자판들은 기본 입력 기능에는 별다른 차이는 없었으므로, 타속이나 피로도를 절실하게 따지지 않는 사람들은 흔히 쓰이는 것과 다른 한글 자판을 쓸 필요를 느끼기 어려웠다.
그러나 KS 완성형 부호계는 표준 부호계답지 않게 표준어에 쓰이는 말도 다 나타내지 못했고, 호적법과 같은 실정법이 시행되는 데에도 걸림돌로 꼽혔다. 한글 부호계의 기본 기능에 결함이 있었지만, 알게 모르게 널리 쓰이는 표준이어서 그 무렵에 KS 완성형 부호계에서 아주 자유로울 수 있는 사람은 거의 없었다.
KS 완성형 부호계에 대한 논란이 커지자 한국표준연구소는 이스케이프 시퀀스(escape sequence)라는 문자판 확장 방식을 써서 부호계를 확장하는 방안을 연구하였다. 그리고 한국표준연구소는 요즘한글 8822자(제1판 1924자 + 제2판 6898자), 옛한글 1781자, 한자 2865자, 특수문자 1500자를 새로운 확장 문자판들에 담아 KS 완성형에 문자를 보충하는 방안을 정리하여 1991년 4월에 체신부에 확장 시안을 제출하였다. 그리고 체신부는 의견 수렴과 심의를 거쳐 한국표준연구소의 안을 전산망 표준 부호계로 제정하려는 뜻을 밝혔고, 1991년 말에 KS C 5657(정보 교환용 부호 확장 세트, 지금의 KS X1002)가 제정되었다.
제1 확장 세트를 규정한 KS C 5657의 문자 구성은 다음과 같다.
- 외국 문자 888자
- 라틴 문자 615자
- 그리스 문자 273자
- 특수문자 275자
- 학술 기호 127자
- 일반 기호 41자
- 괘선 조각 29자
- APL 78자
- 한글
- 옛한글 낱자 27개
- 요즘한글 낱내 1930자 (갂, 갋, 갌, … , 힗, 힜, 힠)
- 옛한글 낱내 1677자 (ᄀᆞ, ᄀᆞᆨ, ᄀᆞᆫ, … , ᅙᅡᆫ, ᅙᅳᆷ, ᅙᅳᆸ)
- 한자 2856자
이스케이프 시퀀스 방식은 ISO 2022의 부호계 확장법을 따르는 문자판을 여러 개 쓸 수 있게 하는 문자판 확장 기술이다. 2바이트 완성형 부호계가 담기는 문자판에는 제어 부호 문제가 걸리지 않는 부호값을 8836개까지 쓸 수 있는데, 이런 문자판을 더 써서 KS C 5601-1987에 들어가지 못한 문자들을 더 넣고자 마련한 것이 KS C 5657이다. 이를테면 KS C 5601-1987에 정의된 KS 완성형 한글 부호계로 넣지 못하는 '똠', '믜', '쑛', '쓔', '씃', '찦', '펲' 등이 KS C 5657에 정의된 보조 부호계에 들어 있다.
KS X 5601(KS X 1001) 및 KS X 5657(KS X 1002)에 나와 있는 문자판을 선택하는 16진수 수열(이스케이프 시퀀스)은 다음과 같다.주8
- KS C 5601
- 기본 문자판
- ESC $ ) C
- 1B 24 28 43
- 기본 문자판
- KS C 5657
- 제1 확장 문자판 G0 집합
- ESC $ ( E
- 1B 24 28 45
- 제1 확장 문자판 G1 집합
- ESC $ ) E
- 1B 24 29 45
- 제1 확장 문자판 G2 집합
- ESC $ * E
- 1B 24 2A 45
- 제1 확장 문자판 G3 집합
- ESC $ + E
- 1B 24 2B 45
- 제1 확장 문자판 G0 집합
KS C 5601의 2350자와 KS C 5657의 1930자에 끼지 못한 요즘한글 낱내자는 6892자는 제2 확장 문자판에서 넣어야 하지만, KS C 5657에는 제2 확장 문자판의 상세한 부호값이 실려 있지 않다.
이스케이프 시퀀스 방식을 써서 '나똠펲'을 넣는다면, 쓰이는 부호값은 이런 식이 된다.
- 기본 문자판 선택 이스케이프 시퀀스 + '나'의 부호값 + 제1 확장 문자판 선택 이스케이프 시퀀스 + '똠'의 부호값 + 제2 확장 문자판 선택 이스케이프 시퀀스 + '펲'의 부호값
시작 부호(SI)와 끝 부호(SO)를 쓴 N 바이트 조합형이나 채움 부호(fill code)를 시작 부호로 쓰는 KS C 5601의 낱자 단위 한글 표변 방법이 그랬던 것처럼, 이스케이프 시퀀스를 쓰는 방법도 프로그램 개발자들이 좋아할 만 한 한글 부호계 운용 방법이 아니었다. 온갖 제어 부호와 제어 규칙이 흔히 쓰이는 통신 환경에서는 이스케이프 시퀀스를 쓰는 방법이 더해지는 것이 대수롭지 않게 보일 수도 있다. 하지만 지난날부터 오늘날까지의 문서 편집 환경에서는 문서 하나에 대체로 한 가지 부호계가 쓰였고, 같은 문서 안에서 부호계를 담은 문자판을 바꾸어 가며 문자들을 나타내는 기술은 잘 쓰이지 않았다. 다른 나라의 문자나 옛한글이 아닌 요즘한글을 쓰기 위해 확장 문자판 여러 개를 살펴야 하는 것은 한글을 다루는 프로그램 개발자들이 받아들이기 어려운 대목이었다.

위는 마이크로소프트웨어 1991년 6월호에 실린 기사 「KSC-56001-1987의 글자판 확장 연구에 관하여」(안대혁)에 함께 실린 광고이다. 안대혁의 기사에 이스케이프 시퀀스 방식을 쓰는 한글 표현 방법의 개요와 문제점이 설명되어 있다.
'한글코드 개정 추진 협의회'는 나중에 공병우의 지원으로 '한국과학기술 청년회'와 함께 한글 문화원이 있던 건물(서울 종로구 와룡동)에 자리잡았다고 한다.주9
그래서 2바이트 조합형을 지지한 민간 전문가들은 KS 완성형 부호계를 땜질해서 쓰려는 정부 기관들의 움직임에 반발하여 '한글코드 개정 추진 협의회'를 만들고 국내 표준 한글 부호계를 조합형으로 개정하기 위한 활동을 시작했다. 1992년에는 문화부와 민간 기업인 한글과컴퓨터가 상용 조합형에 바탕한 요즘한글 · 옛한글 부호계(한컴 2바이트 조합형)와 공세벌식 한글 자판(3-90 자판)을 다룬 연구 보고서인 〈한글코드와 자판에 관한 기초연구〉(이준희 · 김흥규 · 박흥호, , 문화부 · 한글과컴퓨터, 1992.12.)를 펴내기도 했다.주10
1992년에 상용 조합형의 한글 부호값을 따르는 2바이트 조합형 한글 부호계가 KS 완성형 부호계의 보조 문자계로 국내 표준 부호계(KS C 5601-1992)에 들어갔다. 실은 KS C 5601-1987에 이미 다른 2바이트 조합형 부호계가 보조 문자계로 부속서에 실려 있었는데, 먼저 표준으로 지정된 2바이트는 시장에서 쓰이지 않았다. KS C 5601-1992에 상용 조합형 한글 부호계가 표준으로 들어간 것은 시장의 요구와 현실을 확인하여 부속서에 들어가는 2바이트 조합형 부호계를 가장 흔히 쓰이는 것으로 갈음한 것에 뜻이 있었다.
KS C 5657에는 한글 낱내가 더 들어가야 할 제2 확장 문자판의 상세한 부호값을 규정하지 않았다. 부호계 운용이 번거롭고 요즘한글 낱내를 모두 나타낼 수 없는 약점 때문에, KS 완성형 한글 부호계를 보충하려고 KS C 5657으로 제정한 확장 부호계는 프로그램에서 실제로 쓰인 예가 없었다. 다만 KS C 5657은 나중에 유니코드 1.1에 '한글 보충-A'라는 이름으로 한글 문자 집합이 들어가는 근거가 되었는데, 유니코드 2.0에서 큰 폭으로 개정되어 '한글 보충-A'는 곧 폐기되었다.
그럼에도 KS 완성형 부호계는 표준 규격 본문에 들어가는 한글 부호계로서 지위가 바뀌지 않았다. 'KS 조합형' 또는 'KSSM'(Korean Standard Specification Model)주11으로 불리는 2바이트 조합형 표준 부호계는 규격 본문이 아닌 부속서로 끼어 들어갔기 때문에 규격 내용만으로 강제성이나 높은 권위를 띠기는 어려웠다. 2바이트 조합형은 2바이트 부호값이 통신망과 운영체제에서 쓰이는 제어 부호으로 읽힐 수도 있는 제약을 완전히 넘을 수 없었고, 이미 KS 완성형 부호계가 쓰이던 통신망과 프로그램을 갑자기 바꾸는 것도 현실에서 어려운 일이었다. 그래서 대형 통신망들과 프로그램들에서 KS 완성형 부호계가 쓰이던 상황은 크게 달라지지 않았다.
2바이트 방식으로 쓰인 한글 부호계는 어느 쪽으로든 통일되기 어려웠고, 한동안 표준 한글 부호계 문제는 풀릴 기미가 보이지 않았다.
3) 국제 표준에서도 꼬여 가는 표준 한글 부호계
영문 로마자를 비롯한 128개 부호를 담은 7비트 아스키(ASCII) 부호계는 일찌감치 국제 공통 부호계로 자리잡았지만, 그밖의 부호들을 담는 부호계는 한동안 널리 통용되는 표준이 없었다. 여러 문화권에서 쓰이는 부호계들은 부호계 확장 방식이 똑같지 않았고, 같은 부호값이ᅟ 서로 다른 부호와 짝지어지곤 했다.
영문에 쓰이는 로마 문자 이외에 필요한 문자 수가 많지 않은 유럽과 아메리카의 나라들에서는 ISO 8859을 따르는 1바이트(8비트) 확장 부호계를 많이 썼고, 한자 때문에 필요한 문자 수가 많은 동아시아의 나라들에서는 ISO 2022을 따르는 2바이트 확장 부호계를 많이 썼다. 2바이트 확장 방식이 더 쓸 수 있는 부호값은 더 많았지만, 메타 문자와 통신 제어 부호를 피하는 문제를 헤아리지 않더라도 중국 · 대만 · 한국 · 일본 · 베트남 등에서 쓰이는 문자들을 모두 담기에 부호값이 모자랐다. 그래서 1980년대까지 통용되던 기술로는 세계 여러 나라들이 함께 쓸 수 있는 부호계는 나올 수 없었고, 나라마다 자주 쓰는 문자들을 빠듯한 부호 공간에 우선하여 채운 부호계들이 따로 쓰였다.
이 때문에 다른 문화권에 있는 사람끼리 영문이 아닌 글을 주고받는 일은 간단하지 않았다. 이를테면 지난날의 통신 환경에서는 한글과 아랍 문자가 함께 들어간 부호계를 바로 쓸 수 없었으므로, 한글과 아랍 문자를 주고받으려면 글을 파일에 담아 보내는 방법을 써야 했다. 그러자면 보내는 곳과 받는 곳에서 같은 모습으로 글을 보여 줄 프로그램과 글꼴을 서로 갖추고 있어야 하는데, 교류가 없어서 상대방의 형편을 서로 모르던 사이에서는 쉽지 않은 일이다. 나라마다 또는 문화권마다 부호계가 제각각 따로 쓰이는 것은 여러 문화권의 문자들을 함께 지원하는 프로그램이 나오기 어렵게 하는 걸림돌이기도 했다.
웹(web)에서는 이미 1990년대부터 부호계의 종류(코드 페이지, code page)를 바꾸어서 다른 문화권의 글을 보는 기능이 쓰였지만, 그것만으로는 모자랐다. 특정 문화권에서 쓰이는 부호계는 대체로 그 문화권에 쓰이는 문자들에 초점을 맞추어져 있어서, 다른 문화권에 쓰이는 문자들은 모두 다루지는 않았다. 앞에서 본 이스케이프 시퀀스 방식이 여러 문화권의 문자를 한 자리에 나타낼 방안이 될 수 있지만, 글을 편집하는 기능이 있는 프로그램들에서는 이스케이프 시퀀스로 문서 하나에 여러 문화권에서 쓰이는 부호계들을 함께 쓰는 기술이 잘 쓰이지 않았다.
만약 여러 문화권에서 쓰이는 문자들을 모두 담은 부호계가 딱 하나만 세계에서 공통으로 쓰인다면, 다른 문화권 사람과 글을 주고받는 일에 얽힌 고민 거리가 크게 줄어들 수 있다. 대화하는 사람은 상대편이 어떤 부호계와 어떤 프로그램을 알려고 애쓸 필요가 없고, 프로그램 개발자는 한 가지 부호계에 맞추어 프로그램이나 글꼴을 개발하면 된다. 다만 어떤 부호계가 세계 공통으로 여러 문화권에서 널리 쓰일 수 있으려면, 그 부호계를 만들고 보급하는 주체는 널리 쓰이는 프로그램들에 그 부호계가 쓰일 수 있게 프로그램 개발 업계를 이끌 수 있어야 한다. 바꾸어 이야기하면 세계 공통 부호계가 자리잡는 데에는 프로그램 개발 업계의 협조가 필요하다.
유니코드(Unicode, ISO/IEC 10646)는 바로 그런 점들을 헤아려 기획되고 다듬어진 국제 표준 규격이다. 대체로 16비트 이하 부호값으로 문자를 나타낸 지난날의 부호계들과 달리, 유니코드는 21비트까지 써서 최대 111만 4112개 부호값으로 문자를 나타낼 수 있다. 넉넉한 부호계 공간(U+0000 ~ U+10FFFF) 덕분에 오늘날에 쓰이는 모든 문자들과 함께 옛적에 쓰인 문자들까지 담을 수 만큼 부호계로 자리매김할 수 있다. 유니코드는 운영체제 내부나 통신망에 쓰이는 메타 문자나 제어 부호로는 직접 쓰이지 않으므로, 메타 문자나 제어 부호 때문에 자유롭게 쓰지 못하는 부호값이 생기는 문제가 없다.
1991년에 첫 판(1.0)이 나온 유니코드는 1990년대까지는 유니코드를 쓸 수 있는 프로그램이 드물었다. 하지만 유니코드는 유니코드 협회(Unicode Consortium)와 국제 표준화 기구(ISO)에서의 의결 과정에 여러 나라 대표들과 마이크로소프트를 비롯한 쟁쟁한 업체들이 참여하였고, 그 힘으로 2000년대 이후에는 여러 운영체제와 응용 프로그램들에 널리 쓰이는 국제 표준 부호계로 자리잡았다.
2바이트 조합형과 2바이트 완성형을 둘러싼 표준 한글 부호계 논란에서는 문자를 둘 부호계 공간이 모자란 것이 큰 걸림돌이 되어 왔다. 그러므로 부호계 공간이 넉넉한 유니코드를 통하여 어쩌면 표준 한글 부호계 문제가 풀릴 기회가 마련될 수 있을 것으로 기대해 볼 만 했다. 하지만 국내 표준에서 첫 단추를 잘못 끼운 표준 한글 부호계는 국제 표준인 유니코드에서도 이상한 쪽으로 꼬여 갔다.
1991년에 나온 유니코드 1.0에 들어간 한글 부호계의 큰 줄기는 다음과 같다.
- 완성형 부호계주12
- 완성자 2350개 : 가, 각, 간, … , 힙, 힛, 힝 (U+3400 ~ U+3D2D)주13
- 호환용 한글 자모
- 2벌식 낱자 93개 + 채움 문자 1개 (U+3131 ~ U+318E)주14
- 요즘낱자 51개 (U+3131 ~ U+3163)
- 닿소리 낱자 30개 : ㄱ, ㄲ, ㄳ, … , ㅌ, ㅍ, ㅎ
- 홀소리 낱자 21개 : ㅏ, ㅐ, ㅑ, … , ㅡ, ㅢ, ㅣ
- 채움 문자 1개 (U+3164)
- 옛낱자 42개 (U+3165 ~ U+318E)
- 닿소리 낱자 34개 : ㅥ, ㅦ, ㅧ, …, ㆄ, ㆅ, ㆆ (홑낱자 3개 + 겹낱자 31개)
- 홀소리 낱자 8개 : ㆇ, ㆈ, ㆉ, ㆊ, ㆋ , ㆌ, ㆍ, ㆎ (홑낱자 1개 + 겹낱자 7개)
- 요즘낱자 51개 (U+3131 ~ U+3163)
- 2벌식 낱자 93개 + 채움 문자 1개 (U+3131 ~ U+318E)주14
- 반각 한글 낱자
- 두벌식 낱자 51개 + 채움문자 1개
- 닿소리 낱자 30개 : ᄀ, ᄁ, ᆪ, … , ᄐ, ᄑ, ᄒ (U+FFA1 ~ U+FFBE)
- 홀소리 낱자 21개 : ᅡ, ᅢ, ᅣ, … , ᅳ, ᅴ, ᅵ (U+FFC2 ~ U+FFC7, U+FFCA ~ U+FFCF, U+FFD2 ~ U+FFD7, U+FFDA ~ U+FFDC)
- 채움 문자 1개 : U+FFA0
- 두벌식 낱자 51개 + 채움문자 1개
세계 여러 나라의 표준 부호계를 모아서 발표된 유니코드 1.0에는 그림 11-12처럼 KS C 5601에 들어간 KS 완성형 한글 부호계와 같은 차례 및 구성으로 한글 낱내 완성자 2350개가 들어갔다. KS C 5601에 들어간 2벌식 한글 낱자 93개(요즘낱자 U+A4A1 ~ U+A4D3, 옛낱자 U+A4D5 ~ U+A4FE)와 채움 문자 1개(U+A4D4)도 '호환용 한글 자모(Hangul Compatibility Jamo)'라는 이름으로 유니코드에 들어갔다. 반각으로 찍히는 한글 낱자도 요즘낱자만 51개가 들어갔다.주15 주16
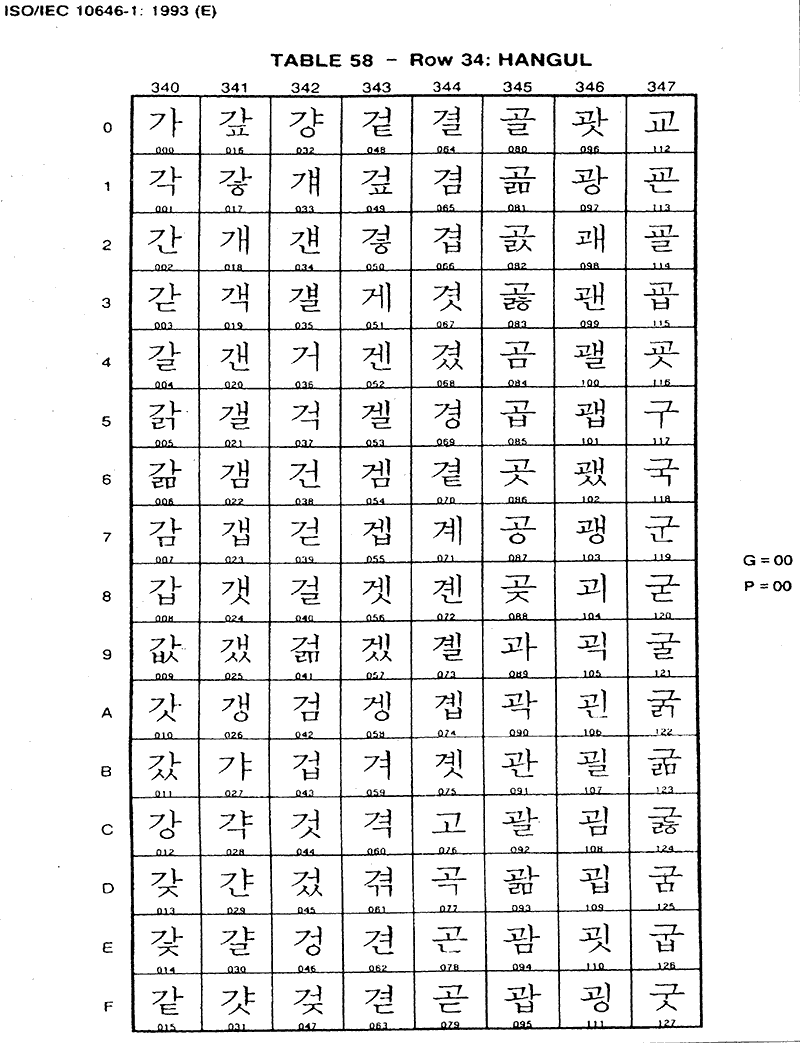
1993년에 나온 유니코드 1.1에 들어간 완성형 및 조합형 한글 부호계의 구성은 다음과 같다.주17
① 완성형 부호계
- 한글 (Hangul) : 낱내 완성자 2350개
- KS C 5601-1987의 완성형 부호계
- U+3400 ~ U+3D2D
- 가, 각, 간, … , 힙, 힛, 힝
- 한글 보충-A (Hangul Supplementray-A) : 낱내 완성자 1930개
- KS C 5657에 실린 한글 확장 세트
- U+3D2E ~ U+44B7
- 갂, 갋, 갌, … , 힗, 힜, 힠
- 한글 보충-B (Hangul Supplementray-B) : 낱내 완성자 2376개
- 중국 연변에서 요구한 6자
- U+44B8 ~ U+44BD
- 믃, 흓, 뽙, 뿥, 쮔, 웘
- KS C 5601 및 KS C 5657에 없는 2370자
- U+44BE ~ U+4DFF
- 갃, 갅, 갧, … , 뭛, 뭜, 뭝
- 중국 연변에서 요구한 6자
② 조합형 부호계
- 첫가끝 부호계
- 3벌식 낱자 238개
- 첫소리 낱자 : 90개 (U+1100 ~ U+1159)
- 가운뎃소리 낱자 : 66개 (U+1161 ~ U+11A2)
- 끝소리 낱자 : 82개 (U+11A8 ~ U+11F9)
- 채움 문자 2개
- 첫소리 채움 (U+115F)
- 가운뎃소리 채움 (U+1160)
- 3벌식 낱자 238개
유니코드 1.1에는 1.0에 없던 한글 완성자 4306개(1930+2376개)가 더하여 들어갔다. 모두 6656개 한글 완성자가 연속된 부호값으로 들어갔지만, 네 묶음(2350자, 1930자, 6자, 2370자)의 가나다 차례짓기가 따로 되어 있었다. 세 묶음은 남한의 낱자 차례를 따랐고, 중국 연변에서 요구하여 들어간 6자는 북조선에서 쓰이는 낱자 차례를 따랐다. 유니코드 1.0판에 이어서 1.1판에서 한글 부호계가 낱자 차례를 지키지 않고 들어가서 유니코드의 완성형 한글 부호계는 매우 누덕누덕한 꼴이 되었다.
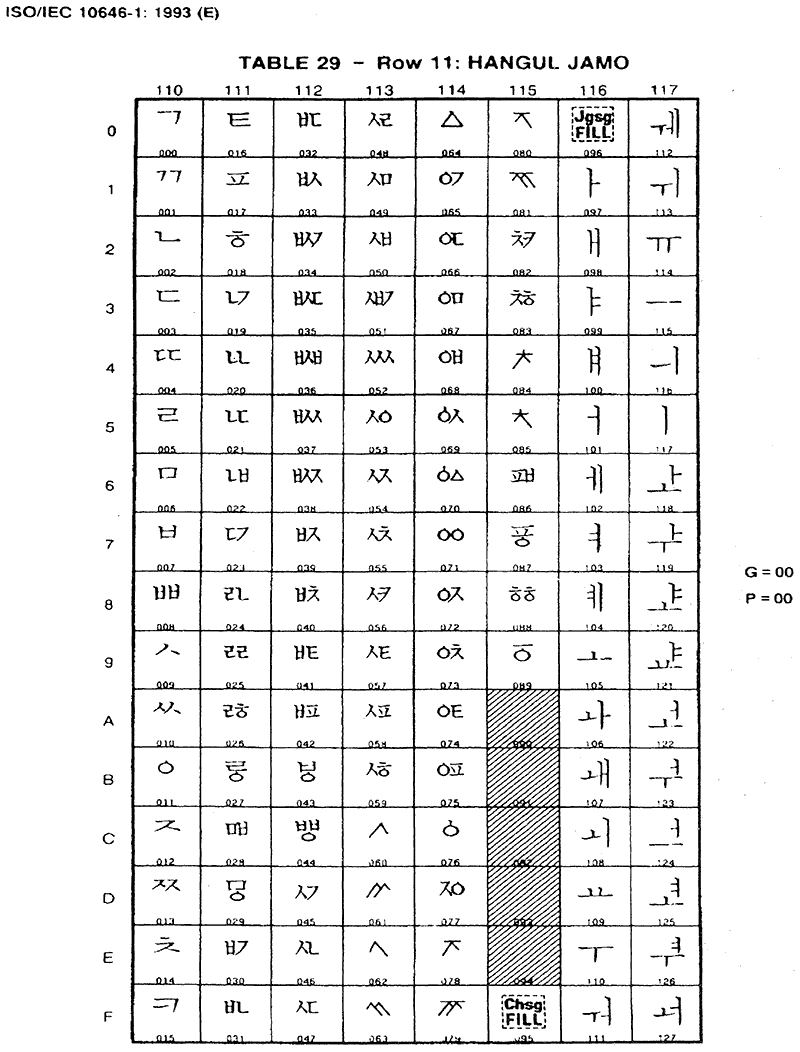

'한글 자모(Hangul Jamo)'라는 이름으로 들어간 첫가끝 부호계는 첫소리/가운뎃소리/끝소리 낱자들을 이어 붙여서(조합하여) 낱자 단위로 한글을 나타내는 첫가끝 조합형에 쓰이는 한글 부호계이다.주18 KS 완성형 부호계에 근거한 호환용 한글 자모는 닿소리와 홀소리만을 가리는 2벌식 체계이지만, 첫가끝 부호계는 닿소리를 첫소리와 끝소리로 나눈 3벌식 체계이다.
첫가끝 조합형은 '조합형'이면서도 먼저 알려진 N 바이트 조합형, 3바이트 조합형, 2바이트 조합형과 다르다고 하여 한때 '새로운 조합형'으로 불렸다. 겹낱자를 조합하는 방법에 따라 적게는 50개, 많게는 수백 개 낱자로 요즘한글과 옛한글 영역에서 쓰이는 낱내 완성자들을 첫가끝 조합형으로 모두 조합할 수 있다. 2바이트 조합형보다 부호값을 훨씬 적게 쓰면서 한글 조합 폭은 더 넓다. 하지만 첫가끝 조합형이 한글 관련 프로그램 개발자들과 연구자들에게 잘 알려지지 못하여 유니코드 1.1가 막 나온 때에는 첫가끝 조합형을 쓸 수 있게 뒷받침할 프로그램과 글꼴이 나오지 못한 상태였다. 첫가끝 조합형은 요즘한글보다 옛한글을 나타낼 방안으로 더 관심을 받았는데, 이 무렵에는 옛한글 낱자를 찾는 문헌 연구가 아직 끝나지 않아서 표준 부호계에 올릴 첫가끝 낱자 구성과 한글 조합 방안을 확정할 수 없었다. 그래서 첫가끝 조합형을 널리 쓸 수 있는 여건이 갖추어지려면 시간이 더 필요했다.
한글 관련 프로그램 개발자들과 관련 전문가들은 대체로 낱자 단위보다 낱내자 단위로 부호값을 매기는 방식을 선호했으므로, 초반의 유니코드 관련 논의에서는 낱내 단위로 나타내는 완성형 한글 부호계에 더 관심이 쏠렸다.
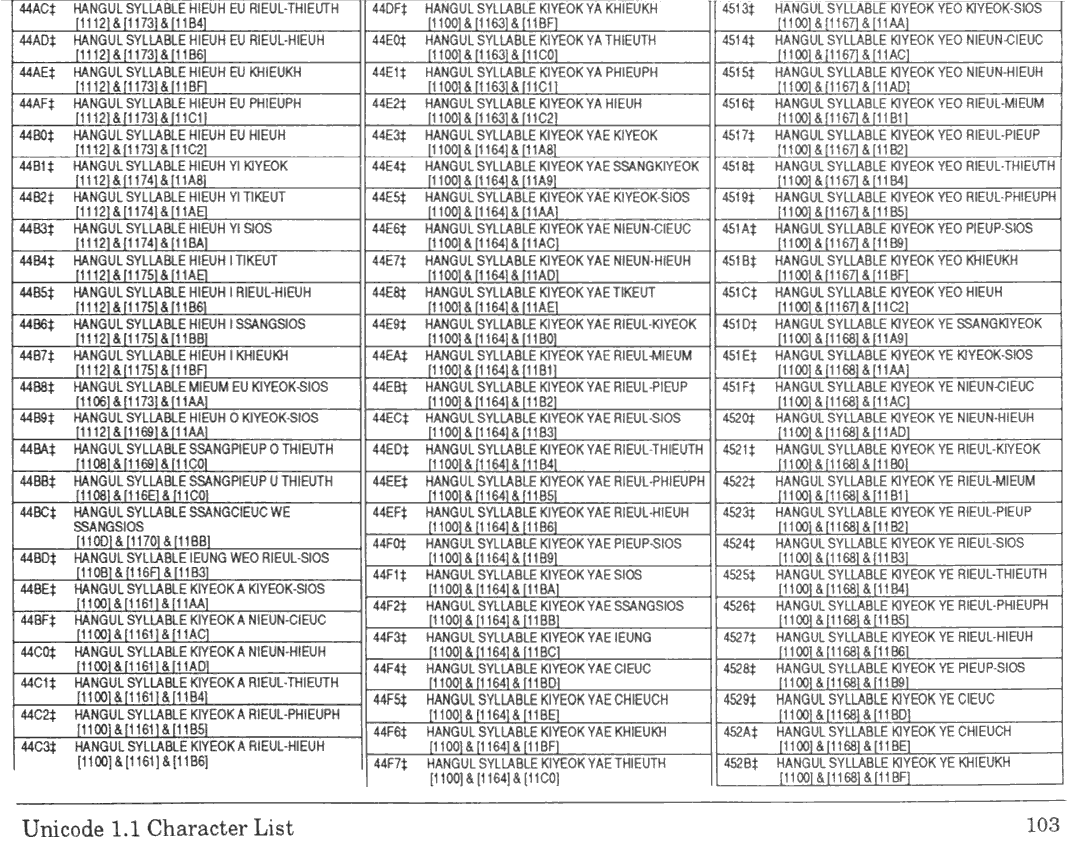
• 따온 곳 : http://www.unicode.org/versions/Unicode1.1.0/appI.pdf
KS 완성형은 한글을 낱자 단위로 분석할 때에 큰 변환표를 써야 했지만, 가나다 차례로 부호값이 매겨져서 변환표 없이 차례짓기를 할 수 있었다. 하지만 유니코드 1.1의 한글 부호계는 낱자 단위로 분석할 때만이 아니라 차례짓기를 할 때에도 변환표를 써야 하고, KS 완성형 부호계에 쓰이는 것보다 더욱 큰 변환표를 써야 하는 꼴이다. 이런 한글 부호계가 유니코드에 그대로 이어진다면, 한글 완성자들이 유니코드에 덕지덕지 들어가는 일이 나중에 거듭될 것이 뻔했다. 그렇게 된다면 프로그램에서의 한글 처리가 번거로워져서 한글 문화권의 프로그램 시장을 오그라뜨릴 수 있었다. 어쩌면 유니코드의 완성형 한글 부호계도 KS C 5657처럼 일부 또는 전체가 명목에만 머무르는 표준이 될 가능성이 있었다.
KS 완성형 부호계로 들끓었던 표준 한글 부호계 문제는 국제 표준 부호계인 유니코드의 초기판에도 이어져서 국내 표준보다 오히려 더 나쁘게 꼬일 위기에 빠졌다.
※ 참고한 자료
- 편집부, 「현행 한글 코드의 문제점과 해결 방안」, 정보시대, 《마이크로소프트웨어》 1989.8.
- 최은혁, 「한글과 컴퓨터의 만남」, 정보시대, 《마이크로소프트웨어》 1990.6.
- 이주희, 「한글 무엇이 문제인가?」, 정보시대, 《마이크로소프트웨어》, 1990.6.
- 원희정, 「호적법 개정안 발표로 덜미잡힌 현행 표준코드」, 정보시대, 《마이크로소프트웨어》, 1990.8.
- 이주희, 「통신선 상에서 문제가 되는 한글 코드」, 정보시대, 《마이크로소프트웨어》, 1990.8.
- 박현철, 「잃어버린 한글을 되찾자」, 정보시대, 《마이크로소프트웨어》 1991.6.
- 안대혁, 「KSC-5601-1987의 글자판 확장 연구에 관하여」, 정보시대, 《마이크로소프트웨어》 1991.6.
- 정내권, 「KS 한글 코드 바뀌어야 한다 - 한글 문화에 적합한 「조합형」으로」, 동아일보사, 《과학동아》 1991.10.
- 강철희, 「정보통신과 한글 코드」, 국어정보학회, 《등불》 제4호, 1991.12.
- 이준희 · 정내권, 〈컴퓨터속의 한글〉, 정보시대, 1991.12.2.
- 이준희 · 김흥규 · 박흥호, 〈한글코드와 자판에 관한 기초연구〉, 문화부 · 한글과컴퓨터, 1992.12.
- 「통신용 소프트웨어와 BBS 접속」, 민컴, 《마이컴》 1992.4.
- 한국 국어정보학회, 《국어정보학회논문집》(제2회 ‘95 컴퓨터 처리 국제 학술회의 참가보고서)(등불 제9호), 1996.8.5.
- 정진용, 「현행 컴퓨터 표준 한글코드 개선되어야 한다」, 대한출판문화협회, 《출판문화》 1992.6. (제29권 5호, 통권 제319호)
- 이기성, 「전자공학의 관점에서 본 컴퓨터와 한글」, 국립국어원, 《새국어생활》 제6권 제2호(’96년 여름), 1996.6.29.
- 『마이크로소프트웨어 CD Issue 1』, 정보시대, 1997.
- 한국표준협회, 〈KS X 1001:1998 한국산업규격 - 정보 교환용 부호계(한글 및 한자)〉 (옛 KS C 5601), 1974.9.27. 제정, 1998.12.31. 개정, 1999.1.25. 발행
- 한국표준협회, 〈KS X 1002:2001 한국산업규격 - 정보 교환용 부호 확장 세트〉 (옛 KS C 5657), 1991.12.31. 제정, 1998.12.6. 개정, 2002.1.2. 발행
- 전상훈, 「민족 문화의 정수, 한글을 한글답게! ― 펩시맨과 똠방각하가 찦차를 탄 이유는…」, 정보시대, 《마이크로소프트웨어》 1998.11.
- 안대혁, 「그 분을 그리며 - 공 박사님, 우리들의 공 박사님」, 국립국어원, 《새국어생활》 제24권 제2호(2014년 여름)
- The Unicode Standard, Version 1.1, 1993. (ISO/IEC 10646-1:1993)
- 그림 11-12 ~ 11-14은 《국어정보학회 논문집》의 부록에 실린 것을 옮긴 것임
- Unicode 1.1 Character List : http://www.unicode.org/versions/Unicode1.1.0/appI.pdf
- 위키백과(wikipedia)
- ISO/IEC 2022 : https://en.wikipedia.org/wiki/ISO/IEC_2022
- 문자 집합 위키 (http://ko.charset.wikia.com)
- KS C 5601-1974 : http://ko.charset.wikia.com/wiki/KS_C_5601-1974
- KS C 5601-1987의 1987년 7월 개정안 : http://ko.charset.wikia.com/wiki/KS_C_5601-1987%EC%9D%98_1987%EB%85%84_7%EC%9B%94_%EA%B0%9C%EC%A0%95%EC%95%88
![미리보기 그림 - [온라인 한글 입력기] 보태고 고친 풀어쓰기 기능](/thumbnail/1/JP_Thumb/coverphoto/thumb_1702892062.gif.webp)




덧글을 달아 주세요
전마머꼬 2020/02/04 15:27 고유주소 고치기 답하기
20년전에 워드프로세서 시험칠 때 조금 배웠던(시험에 나오니까)
내용을 다시 자세히 보니 새롭습니다.
현 유니코드 구현이 조합형을 적은 비트에 잘 쑤셔넣은 발전형인 것 같은데.
지식이 쌓여가며 발전하는 모습을 수십년 뒤에 보면 참으로 재미나네요.
팥알 2020/02/04 16:22 고유주소 고치기 답하기
저는 워드프로세서 1회 시험을 봤었는데, 기억이 가물가물하지만 그 때는 초장기여서 그랬는지 전자계산기 이론이 많고 한글 부호계에 관한 내용은 다룬 기억이 안 나네요. 나중에 한 번 워드 시험에 관한 이야기도 해 보고 싶네요.