표준이 된 세벌식? - (4) 옛한글을 나타내는 표준 방안이 된 첫가끝 조합형
1) 완성형 한글 부호계로 나타내기 어려운 옛한글
앞에서 살핀 유니코드 2.0에 들어간 완성형 한글 부호계는 한글을 낱내자 단위로 부호값을 붙여 처리하는 것을 선호하는 한글 입출력 프로그램 개발자들의 성향을 따른 꼴이다. 11172개 부호값을 쓰는 이 완성형 한글 부호계로 67개 낱자(첫소리 19개, 가운뎃소리 21개, 끝소리 27개)로 조합할 수 있는 요즘한글은 잘 나타낼 수 있지만, 모든 유형의 한글을 나타내지는 못한다. 한글에는 ᅀᅠ · ᅙᅠ · ᄼᅠ 같은 홑낱자들과 ᅑᅠ · ᅟᆋ · ꥲᅠ같은 겹낱자들처럼 요즘한글에 쓰이지 않는 낱자들이 더 쓰이는 이른바 '옛한글' 영역이 더 있기 때문이다.
- 요즘한글 낱내자 : 가 ~ 힣 (U+AC00 ~ U+D7A3)
- 옛한글 낱내자 : 가ᇫ, 오ᇢ, ᅌᅡ, ᄫᅥ, ᄒᆞᆫ, ᄒᆡ, ᄋힶ, ᄣᆞᆯ, ᅑᅡ, …
- 미완성 낱내자 : ᅟᅡᆫ, ᄀᅠᆫ, ᄑᅠᆻ, ...
옛 문헌에 실린 옛한글은 옛 우리말이나 다른 나라 말을 나타내는 데에 주로 쓰였다. 요즈음에도 ᄒᆞᆫ저옵서예(어서 오세요), ᄋᆏ치(여치), 여ᇬ다(얹다), 흐ᇘ(흙) 같은 사투리를 나타낼 때에 옛한글 영역으로 여기는 낱내자들이 쓰일 수 있다. 앞의 전상훈의 글에서 이야기된 미완성 낱내자도 유니코드의 완성형 부호계로는 나타낼 수 없다.

- 사진 : 대불정여래밀인수증요의제보살만행수능엄경(언해) 권3 (보물 제948-2호) (大佛頂如來密因修證了義諸菩薩萬行首楞嚴經(諺解) 卷3)
- 사진 따온 곳 : 문화재청 국가문화유산포털 (공공누리 저작물) (www.heritage.go.kr/heri/cul/culSelectDetail.do?pageNo=5_2_1_0&ccbaCpno=1123109480200)
67개 낱자로 조합할 수 있는 1만 1172개 요즘한글 완성자(낱내자)는 마이크로소프트의 도움을 받아 어렵사리 유니코드의 노른자위인 BMP(Basic Multilingual Plane) 영역에 올릴 수 있었지만, 옛한글 완성자는 유니코드에 올리기에 수가 너무 많다. 1993년의 유니코드 1.1에는 238개 첫가끝 낱자와 2개 채움 문자가 들어갔는데, 이 첫가끝 낱자들로 조합할 수 있는 완성/미완성 한글 낱내자는 50만 개가 넘는다.주1 2009년에 나온 유니코드 5.2에는 첫가끝 낱자가 355개로 늘었고, 첫가끝 낱자와 채움 문자로 조합할 수 있는 완성/미완성 한글 낱내자는 163만 8000여 개로 늘었다.주2 하지만 옛한글 낱자들은 문헌에 잠깐 나오고 거의 쓰이지 않은 것이 많아서, 옛 문헌에 실린 예를 찾을 수 있는 옛한글 완성자 수는 겨우 5천 자 남짓이다.주3
조합할 수 있는 옛한글 완성자를 모두 유니코드에 올리는 것은 실현 가능성도 없고 명분도 서지 않는 일이다. 유니코드에서 쓸 수 있는 부호값이 111만 4112개이고, 2019년의 유니코드 12.1에 들어간 문자 수는 모두 합쳐 13만 7994개이다. 이론을 따져 조합할 수 있는 한글 완성자 수가 유니코드로 쓸 수 있는 부호값의 수를 넘어선다. 실제로 쓰인 적이 있는 한글 완성자는 요즘한글 낱내자까지 더해도 2만 개를 넘지 않으므로, 유니코드를 잘 쓰이지 않는 한글 완성자들로 가득 채우는 것은 형평에 맞지 않다. 100만 자가 넘는 한글 완성자들 하나하나에 부호값을 매겨 주석을 붙이고 목록을 만드는 일도 현실에 맞지 않다.
완성자 수를 줄여서 옛한글을 완성형으로 나타내는 방안도 있다. 하지만 새로 알려지는 옛 문헌에서 옛낱자가 더 발견될 수도 있고, 옛 문헌에 실리지는 않았어도 옛 문헌의 내용이나 어법을 설명할 때에 더 쓰이는 낱자나 낱내자도 있다. 더 필요한 낱자가 생길 때마다 부호계에 낱내자를 더 넣는다면, 옛한글을 다루기 위한 완성형 부호계도 유니코드 1.1의 완성형 부호계처럼 다루기 까다로운 누더기 부호계가 되어 갈 수 있다. 실제로도 1993년에 유니코드 1.1가 발표된 뒤에 문헌 조사로 발굴된 옛낱자들이 더 있었으므로, 옛한글을 다루는 한글 부호계를 낱내자 단위로 마련하는 것은 미래까지 헤아리는 계책이 될 수 없었다.
2) '21세기 세종계획'과 '첫가끝 조합형'
'첫가끝 조합형'은 첫소리·가운뎃소리·끝소리 낱자들에 독립된 부호값에 매기고, 낱자들의 부호값을 이어 붙여서 글꼴 처리를 통하여 낱내자를 나타내는 한글 조합 방식이다. 끝소리(받침)가 없으면 '첫+가' 꼴로 낱내를 조합하고, 끝소리가 있으면 '첫+가+끝' 꼴로 낱내를 조합한다. 겹낱자를 부호계에 모두 올리는 방식으로 첫가끝 조합형을 운용한다면, 웹에서 흔히 쓰이는 유니코드 부호 매김 방식(유니코드 인코딩 방식)인 UTF-8을 기준으로 6바이트(첫+가) 또는 9바이트(첫+가+끝)를 써서 한글 낱내 하나를 나타낼 수 있다.주4
1993년에 나온 유니코드 1.1에 들어간 첫가끝 부호계의 낱자 및 채움 문자 240개의 구성은 다음과 같다.
- 요즘한글 낱자 67개
- 첫소리 낱자 19개
- U+1100 ~ U+1112
- ᄀᅠ, ᄂᅠ, ᄃᅠ, … , ᄐᅠ, ᄑᅠ, ᄒᅠ
- 가운뎃소리 낱자 21개
- U+1161 ~ U+1175
- ᅟᅡ, ᅟᅢ, ᅟᅣ, … , ᅟᅳ, ᅟᅴ, ᅟᅵ
- 끝소리 낱자 27개
- U+11A8 ~ U+11C2
- ᅟᅠᆨ, ᅟᅠᆩ, ᅟᅠᆪ, … , ᅟᅠᇀ, ᅟᅠᇁ, ᅟᅠᇂ
- 첫소리 낱자 19개
- 채움 문자 2개
- 첫소리 채움 (U+115F)
- 가운뎃소리 채움 (U+1160)
- 옛한글 낱자 171개
- 첫소리 낱자 71개
- U+1113 ~ U+1159
- ᄓᅠ, ᄔᅠ, ᄕᅠ, … , ᅗᅠ, ᅘᅠ, ᅙᅠ
- 가운뎃소리 낱자 45개
- U+1176 ~ U+11A2
- ᅟᅶ, ᅟᅷ, ᅟᆦ, … , ᅟᆠ, ᅟᆡ, ᅟᆢ
- 끝소리 낱자 55개
- U+11C3 ~ U+11F9
- ᅟᅠᇃ, ᅟᅠᇄ, ᅟᅠᇅ, … , ᅟᅠᇷ, ᅟᅠᇸ, ᅟᅠᇹ
- 첫소리 낱자 71개
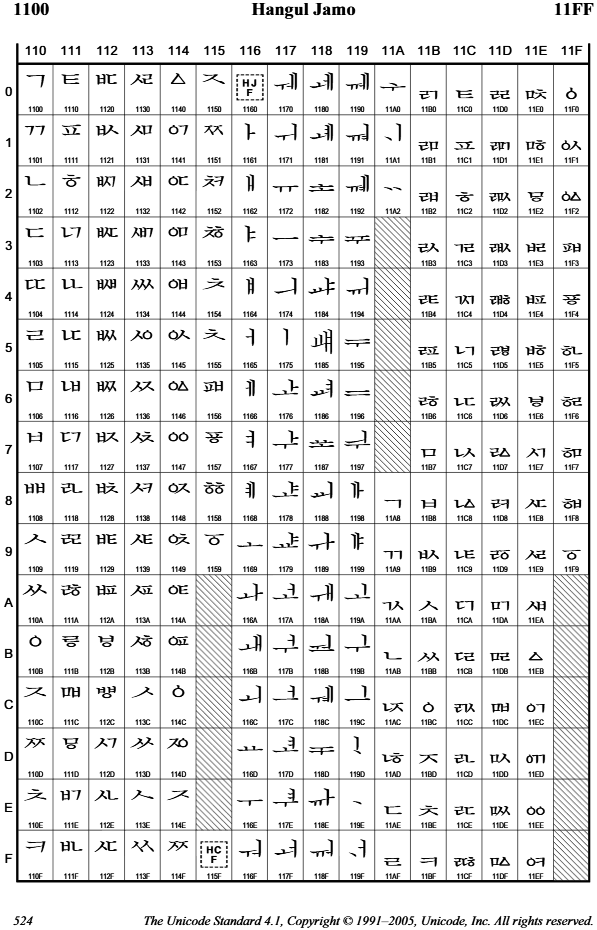
• 따온 곳 : The Unicode Standard, Version 4.1 Archived Code Charts (https://www.unicode.org/Public/4.1.0/charts/CodeCharts.pdf)
유니코드 1.1가 나온 1993년은 옛한글 낱자를 찾기 위한 문헌 조사가 끝나지 않은 때였다. 그 뒤에도 문헌 연구로 새로 알려지는 옛한글 겹낱자들이 더 있었고, 유니코드 1.1에 없는 옛낱자도 학계의 문헌 연구에 필요했다. 옛한글을 다루는 프로그램들은 유니코드를 쓰지 않고 다른 방법으로 옛한글을 나타냈다. 1990년대 초·중반에 도스에서 쓰인 'ᄒᆞᆫ글'은 ㅿ, ㆁ, ㆍ처럼 자주 쓰이는 몇몇 옛낱자만 조합형으로 처리하고 자주 쓰이지 않는 옛낱자가 들어간 낱내자들은 완성형으로 처리했다. 유니코드를 쓰는 시대로 접어든 1990년대 후반부터는 유니코드의 사용자 정의 영역(PUA)을 쓰는 '한양 PUA 코드'가 옛한글이 들어간 문헌 내용을 전산 자료로 옮기는 일에 임시 부호계로 쓰였다. 한양 PUA 코드에서 옛한글을 나타내는 데에 주로 쓰인 한글 부호계는 완성자 5299개를 담은 완성형 부호계였다.주5 주6
한양 PUA 코드를 쓰는 옛한글 표현 방식은 유니코드 표준 영역이 아닌 사용자 정의 영역을 임시로 쓰는 방안이어서 장래에까지 프로그램 및 글꼴 지원을 끌어 낼 권위는 없었다. 컴퓨터를 쓰는 어느 환경에서나 옛한글을 넣고 나타낼 기반이 마련되려면, 새로 발견된 옛한글 겹낱자들을 유니코드의 첫가끝 부호계에 정식으로 넣고 프로그램으로 구현할 옛한글 처리 방안을 뚜렷하게 마련해야 했다.
한양 PUA 코드는 국책 사업으로 진행된 '21세기 세종계획'과 얽혀 있다. 국립국어원과 문화관광부가 주관한 '21세기 세종계획'에서는 기관/학계/산업체의 협동 작업으로 15세기부터 1920년대에 나온 옛 문헌들을 모아 그 내용들을 전산 자료로 옮기고, 표준 문자 부호계에 더 넣을 옛한글 낱자들을 추리고 옛한글 조합 방안을 마련하는 연구 사업도 함께 진행해 나갔다.주7 한양 PUA 코드가 '21세기 세종계획'의 초·중반 단계에서 쓰였지만, '21세기 세종계획'의 마지막 단계에 표준안으로 제안된 옛한글 표현 수단은 '첫가끝 조합형'이었다.

2004년에 '21세기 세종계획'의 주축이 된 고려대학교 '비표준 문자 등록 센터'의 산하에 있던 '옛한글정보처리연구위원회'는 아래의 그림 13-4에 보이는 것처럼 '옛한글 자료 코드 표현의 기본 원칙 및 지침'이라는 이름으로 국내외 표준으로 제안할 옛한글을 처리하는 원칙과 방법을 마련하였다.
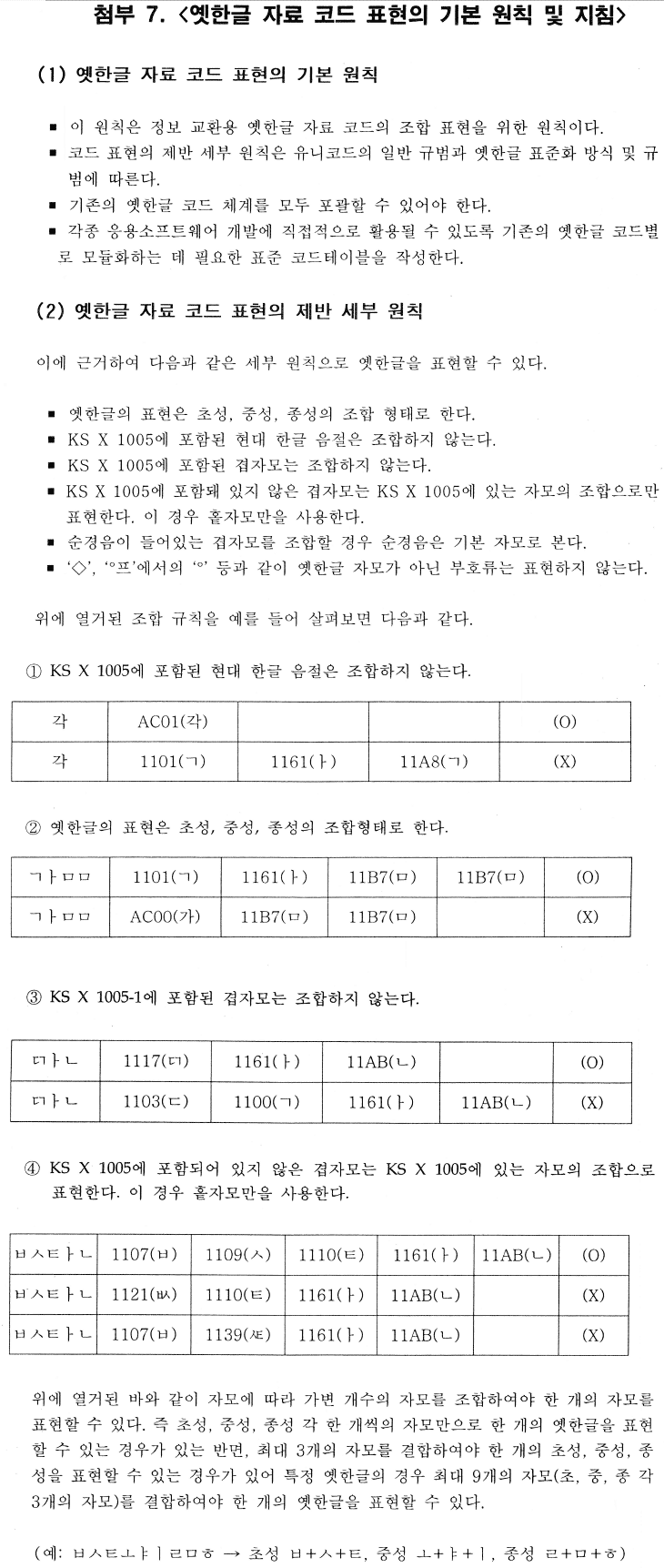
이 조합 방안을 따르면, 1벌 낱자를 3개까지 두어서 낱내자 하나에 낱자를 9개까지 담을 수 있다. 이를테면 'ᄩᅪᇌ'은 아래처럼 낱자를 이어 붙여서 나타낼 수 있다.
- ᄇᅠ + ᄐᅠ + ᅟᅩ + ᅟᅡ + ᅟᅠᆯ + ᅟᅠᆨ + ᅟᅠᆺ
(첫① + 첫② + 가① + 가② + 끝① + 끝② + 끝③)
이 방안을 따른다면, 부호계에 이미 들어간 홑낱자를 이어 붙여서 부호계에 없는 겹낱자들을 모두 나타낼 수 있다. 부호계에 겹낱자를 따로 더 넣지 않아도 이론상 조합할 수 있는 한글 유형을 모두 나타낼 수 있는 셈이다.
'옛한글정보처리연구위원회'가 중심이 되어 마련한 '옛한글 자료 코드 표현의 기본 원칙 및 지침'(그림 13-4)의 내용은 2014년 11월에 국제표준화기구(ISO)에 제안되었다. 그러나 국제 표준화 기구(ISO)와 유니코드 협회는 이 방안을 따를 때에 NFD → NFC로 바꾸는 유니코드 정규화(unicode normalization)를 거치면 'ᄩᅪᇌ'이 '첫① + 첫② + 완성자 + 끝③'인 'ᄡᅠ퇅ᅟᅠᆺ'으로 해석될 수 있는 문제가 있음을 꼬집었다. 그래서 한글을 나타내는 폭을 넓히는 것에 초점을 맞춘 2004년의 이 조합 방안은 포기할 수밖에 없었다. 2006년 5월에 국제표준화기구와 유니코드 협회는 한국 쪽 제안자들과 논의하여 모든 첫가끝 조합용 겹낱자들을 BMP 영역에 등록한다는 원칙을 잠정적으로 결정하였고,주8 한국 쪽 제안자들은 추가로 등록할 겹낱자 목록을 제출해 달라는 요구를 받았다.
그래서 국립국어원이 주관하여 '옛한글정보처리연구위원회'는 2006년 7월 7일과 7월 24일에 회의를 열어 먼저 마련해 제안했던 '옛한글자모 확장목록'에서 옛한글 겹낱자 121자 가운데 4자를 뺀 117자의 목록을 다시 제안하기로 하였다.주9 이미 알려져 있던 첫가끝 조합 방안대로주10 유니코드 1.1에 들어간 첫가끝 부호계처럼 ퟁ(ㅣ+ㅗ+ㅣ), ᅟᅠᇖ(받침 ㄹ+ㅅ+ㅅ)을 비롯한 겹낱자들을 모두 유니코드에 올리고 '첫+가' 또는 '첫+가+끝' 꼴로 낱내자를 조합하는 방법을 옛한글을 나타내는 표준 방안으로 삼기로 결정하였다.

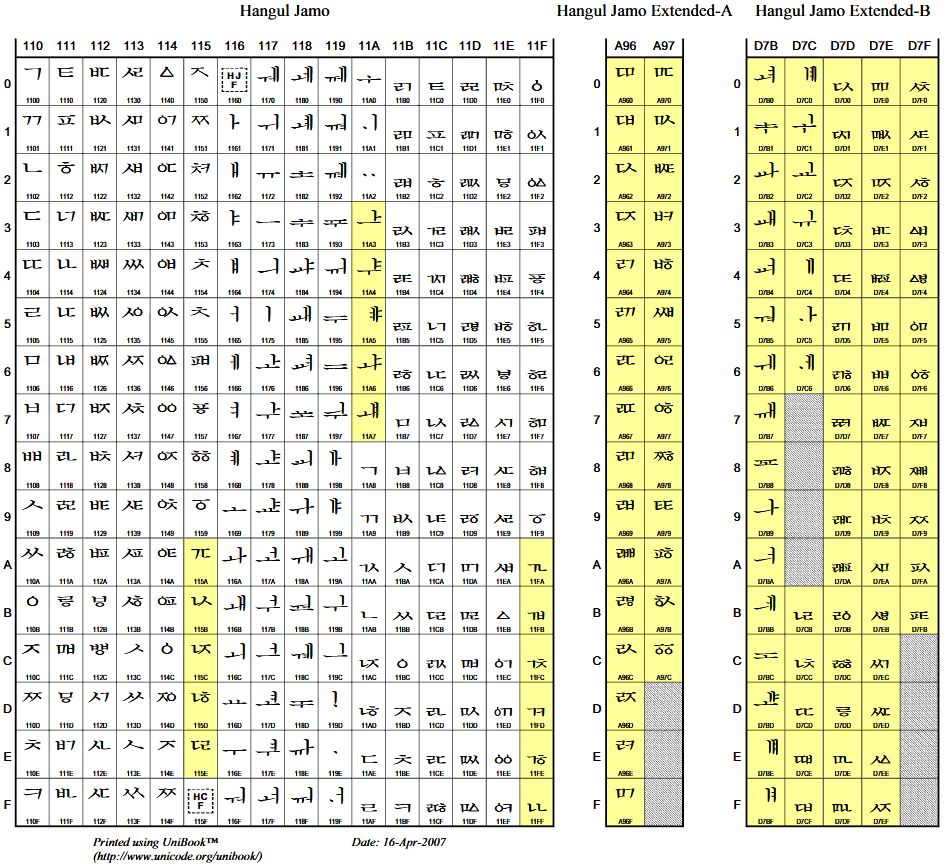
- 따온 곳 : ISO/IEC JTC1/SC2/WG2 N3242, L2/07-103, 2007-04-16
(http://std.dkuug.dk/jtc1/sc2/wg2/docs/n3242.pdf) (발췌하여 이어 붙임) - 노란 칸의 겹낱자들이 유니코드 5.2에 더하여 들어간 첫가끝 낱자임
2006년까지의 연구로 유니코드에 더 넣을 옛한글 낱자 목록과 유니코드로 옛한글을 나타내는 방법이 정리되었다. 이 내용을 2007년의 유니코드 회의(ISO/IEC JTC1/SC2/WG2N3242)주11에서 제안하였고, 국내 표준(KS X 1026-1: 정보교환용 한글 처리지침)으로 제정하였다. 그리고 2008년에 유니코드와 ISO 회의의 표결을 거쳐서 2009년에 발표된 유니코드 5.2에 반영되었다.주12 이렇게 하여 그림 13-6에 보이는 것처럼 유니코드 1.1 이후에 문헌 조사를 통하여 더 발굴된 옛한글 겹낱자 117개가 국내외 표준 부호계에 더하여 들어가는 것으로 21세기 세종계획이 중심이 된 한글 부호계 표준화 작업이 마무리되었다.

위는 유니코드 표준 5.2판에서 첫가(LV) 또는 첫가끝(LVT) 낱자로 이루어지는 첫-가-끝 낱내(Lead-Vowel-Trail Syllable)의 경계를 가리는 원리와 보기를 설명한 부분이다. 위의 표(Table 3-14)에서 1와 3은 첫소리 채움 문자(Lf)와 가운뎃소리 채움 문자(Vf)를 써서 첫가끝 낱내의 경계를 유니코드 표준에 맞게 가린 보기이고, 2은 유니코드 표준에 맞지 아니한 보기이다.
국내 표준인 KS X 1026-1(정보교환용 한글 처리지침)에도 위의 유니코드 표준처럼 첫가끝 조합형을 운용하는 원리를 설명한 내용이 실려 있다.
유니코드 5.2에 더하여 들어간 첫가끝 한글 부호계와 조합 방안에는 아쉬운 점이 있다. 문헌 조사를 미리 마치지 못한 탓에 첫가끝 낱자들이 시차를 두고 유니코드에 들어가서, 처음 들어간 낱자들과 나중에 들어간 낱자들의 부호값이 가나다 차례와 어긋나게 되었다. 이 때문에 첫가끝 조합형으로 넣은 한글 내용을 정확하게 차례짓기하려면 따로 알고리즘을 써야 한다.주13 또 유니코드 정규화 문제에 걸려 홑낱자를 이어 붙여 겹낱자를 만드는 방안을 쓰지 못하게 되었으므로, 만약에 옛 문헌에서 아직 알려지지 않은 겹낱자가 더 발견되면 유니코드에 겹낱자를 더 올려야 할 수 있는 짐을 안게 되었다.
그렇지만 겹낱자를 모두 완성자로 나타내는 유니코드의 첫가끝 방식은 프로그램에서의 한글 처리가 더 손쉬운 꼴이다. 낱내자를 이루는 낱자 조합 유형이 '첫+가' 또는 '첫+가+끝'밖에 없으므로, 겹낱자의 구성을 알기 위한 복잡한 처리가 필요가 없고 낱내 경계를 가리는 처리도 간편하여 한글을 넣거나 지우는 처리가 손쉽다. 이와 달리 홑낱자를 이어 붙여서(조합해서) 겹낱자를 나타낸다면, 낱내자 경계만이 아니라 낱자 경계도 따로 가려야 해서 한글 처리가 더 까다롭다.
유니코드 5.2이 나온 직후까지 옛한글을 나타내는 데에 가장 흔히 쓰인 한글 부호계는 첫가끝 부호계가 아니라 '한양 PUA 코드'로 불린 완성형 부호계였다. 한양 PUA 코드는 '21세기 세종계획'의 초기 단계에서 쓰기 위해 임시로 마련한 비표준 부호계였는데, '국어 정보화'라는 이름으로 옛한글을 담은 문헌 내용을 전산화하는 국책 사업에 쓰이다 보니 표준 아닌 표준처럼 어정쩡한 지위를 누렸다. ᄒᆞᆫ글, 훈민정음, MS 워드 같은 문서 편집기(워드프로세서)로 한양 PUA 코드를 쓰는 문서를 만들고 볼 수 있었지만, 웹에서 옛한글을 보려면 글꼴(새굴림 등)을 따로 깔아야 했다.
2000년대까지는 널리 쓰이는 상업용 제품 가운데 유니코드 1.1에 바탕한 첫가끝 조합형을 지원하는 프로그램은 마이크로소프트의 제품군(MS 오피스)을 빼면 거의 없다시피 했다. 2000년대에 표준화 작업을 매듭지은 첫가끝 한글 부호계가 어디에서나 널리 쓰일 수 있으려면, 흔히 쓰이는 프로그램들의 한글 입출력 기능을 새로운 유니코드에 맞게 바꾸어 가야 했다.
'21세기 세종계획'의 옛한글 분야 연구에 참여한 기관·학계·업계의 전문가들은 1990년대에 기틀이 잡힌 첫가끝 조합형을 보완하여 문헌 조사로 알려진 옛한글을 모두 나타낼 수 있는 한글 조합 방안을 마련하였고, 이를 국내 표준(KS X 1026-1)과 유니코드에 반영시켰다. 1980~1990년대에 나온 많은 표준 한글 부호계들은 학계나 업계의 의견과 요구를 고루 듣는 과정을 건너뛴 채로 제정되었지만, '21세기 세종계획'에서는 국어학계가 먼저 나서서 문헌 조사를 비롯한 기초 연구를 진행한 뒤에 그 성과를 근거로 하여 업계와 정부 기관이 국내외 표준 부호계 내용을 함께 의논해 나가는 모양새가 되었다.
이렇게 기관/학계/업계가 함께 참여하여 첫가끝 조합형의 내용(첫가끝 부호계와 첫가끝 부호계 운용 방법)을 국내외 표준에 올린 것은 한글 입력 프로그램과 글꼴을 개발하는 기업들과 개발자들이 움직이는 동기와 근거가 되었다. 문서 편집 프로그램인 'ᄒᆞᆫ글'은 2010년 제품부터 첫가끝 조합형을 옛한글 표현 수단으로 지원했고, '윈도우'(Windows)를 비롯한 운영체제들도 바뀐 유니코드에 따라 첫가끝 조합형을 지원하는 입력기와 GSUB/GPOS 기능이 들어간 가변폭 글꼴을 차츰 갖추어 첫가끝 조합형을 널리 쓸 수 있는 기반을 마련하였다. 아직도 첫가끝 조합형에 대한 프로그램 지원에는 미흡한 점이 있지만,주14 2010년대에는 첫가끝 조합형이 운영체제 차원에서 지원되면서 웹(web)처럼 널리 쓰이는 매체에서도 옛한글을 바로 나타낼 수 있는 기반이 마련되었다.
1980년대의 국내 표준부터 몸살을 앓아 온 표준 한글 부호계 문제는 1990년대에 국제 표준인 유니코드에서 더욱 꼬일 뻔 했지만, 유니코드를 개정하고 보완하는 작업을 거쳐 더 나은 쪽으로 풀릴 수 있었다. 어렵사리 개정한 유니코드 2.0의 완성형 한글 부호계는 완성형이면서도 낱내자들이 가나다 차례로 놓여서 조합형을 바라던 프로그램 개발자들도 반길 수 있는 꼴이었다. 그러나 이 완성형 한글 부호계로는 미완성 한글과 옛한글까지 나타내지 못하므로, 옛한글까지 나타낼 방안을 따로 마련해야 했다. 그래서 기관·학계·업계 전문가들은 '21세기 세종계획'이라는 연구 사업을 구심점으로 하여 유니코드 1.1부터 들어간 첫가끝 부호계에 더 찾아낸 옛낱자들을 더하여 넣고 첫가끝 조합형으로 옛한글을 나타내는 구체 방안을 확정하여 유니코드 표준에 반영시켰다. 이렇게 하여 11172개 낱내자를 담은 완성형 부호계를 주로 쓰면서 완성형으로 나타내지 못하는 한글을 첫가끝 조합형으로 나타내는 것으로 2000년대에 한글 부호계 표준화 작업이 매듭지어졌다.
▣ 21세기 세종계획과 유니코드
'21세기 세종계획'은 국어학계가 주축이 되어 기관과 학계와 산업계 관계자들이 폭넓게 참여한 연구 사업이다. 이 연구 사업은 크게 3단계로 이루어졌는데, 다음은 그 내용을 간추려 본 것이다.
- 제1단계 (1998~2000)
- 자문기구 구성
- 연구 설비 구축
- 비표준문자 등록・관리 체계 수립
- 비표준문자 처리 방안 연구
- 옛한글 5291자 확보
- 옛한글 기초 문헌 데이터베이스 구축
- 옛한글 정보화 산학협동 심포지엄 개최
- 한자 정보 데이터베이스(48027자) 구축/제공
- 한자 자형 제작
- 소식지 《비표준문자등록센터 소식》(1~10호), 《문자연구센터소식》 (11~22호) 발간 시작
- 제2단계 (2001~2003)
- 옛한글 문헌 연구
- <옛한글 정보 데이터베이스> 용례 정보 추출
- 2237개 자형 수집
- 정리된 61434자(옛한글 6자 포함) 처리
- 옛한글 문헌 추가 수집/분석
- 옛한글정보처리연구위원회 구성 및 회의 개최
- 옛한글 자모 세트 선정 및 배열 방안 워크숍 개최
- 옛한글 표준화 방식 및 규범 시안 제안
- 한자 문헌 연구
- 한자정보DB훈독 정보 추가 (총 4'7435자)
- 유니코드 한자(V3.0) 통계 분석을 위한 기초연구 (총 1154'7746자 한문 문헌 자료 수집)
- 고전 전산화를 위한 한자 이체자 처리 방안 산학협동 심포지엄 개최
- 수집된 비표준한자 국제 표준화(Ext. C1) 지원
- 비표준문자 수집 및 등록 : 총 2264자
- SuperCJK 통계 추출기 개발
- 종합보고서(21세기 세종계획 문자코드 표준화 연구) 발간 시작 (2003~2007)
- 옛한글 문헌 연구
- 제3단계 (2004~2007)
- 비표준문자 수집・정리 및 국제 표준화 지원
- 총 1,096자 수집, 신출한자 432자 추출
- 제22차, 제23차 IRG회의 참석
- SuperCJK Ext.C1 제출한자의 정보 교정・수정
- SuperCJK Ver.14.0 한자 정보 데이터베이스 구축
- <SuperCJK 14.0 검색시스템> 개발
- <신출한자의 처리와 국제 표준화> 워크숍 개최
- <Ext.C2 한국측 제안 한자 목록> 작성, 검토
- 옛한글의 국제 표준화를 위한 연구와 지원 체계 확립
- 주요 워드프로세서의 옛한글 코드 체계와 표현 방식 분석
- 국가표준코드의 옛한글 코드 체계 및 표현 방식 분석
- 옛한글 자료 코드 표현 기본 원칙, 방안, 지침 수립/인준
- 비표준문자 수집・정리 및 국제 표준화 지원
이미 1980년대부터 몇몇 연구가들은 표준 부호계에 들어가지 못한 옛한글과 한자를 전산 기기로 나타내는 방법을 연구하고 프로그램으로 구현하는 작업을 벌였다. 프로그램을 새로 고안하거나 이미 쓰이던 문자 입출력 프로그램을 이용하여 더 많은 문자들을 나타낼 수 있게 고친 프로그램을 선보이기도 하였고, 프로그램을 구현한 방법이나 부호계 내용을 문헌에 싣기도 하였다. 이런 노력들이 모여서 그 무렵에 쓰이던 한글 입출력 프로그램들은 점차 더 많은 한글/한자/기호 문자들을 나타내는 쪽으로 발전해 갔다.
'21세기 세종계획'의 비표준 문자 연구 사업은 문헌 정보에 얽힌 분야들에서 여러 연구가들이 쌓은 정보와 업적을 한데 모으고 정리하여 누구나 누릴 수 있는 꼴로 만들어 나가는 일에 힘쓴 종합 연구 사업이었다. 21세기 세종계획에서는 한글과 한문 등이 담긴 옛 문헌들의 내용을 전산 자료로 옮기는 작업을 벌였는데, 이는 말뭉치를 만들어 내용을 빠르게 찾거나 통계 분석에 이용하기 위한 기초 작업이다. 이를 바탕으로 학계의 입장을 정리하면서 표준으로 제안할 내용을 기관 및 업계와 협의하는 과정을 꾸준히 밟아 나갔다.
아직 표준 부호계에 오르지 못한 문자들이 국내외 표준 부호계에 일관성 있게 실리고 여러 프로그램들에서 널리 쓰일 기반까지 마련되려면, 여러 주체들의 협조를 이끌어 내고 국제 활동까지 연계해 나갈 구심점이 필요했다.
21세기 세종계획의 제1단계와 제2단계에서는 옛 문헌에 쓰인 한글과 한자 정보들을 통계 분석과 용례 분석을 할 수 있도록 자료기지(데이터베이스)로 쌓아 올리는 작업이 이루어졌다. 이 과정에서 '한양 PUA 완성형'이라는 유니코드 사용자 정의 영역을 쓰는 임시 부호계가 옛한글을 비롯한 비표준 문자들을 나타내는 데에 쓰였다.주15 그리고 마지막 단계인 제3단계에서 옛한글을 나타내는 방법인 첫가끝 부호계와 첫가끝 조합형 내용을 정리하여 유니코드에 정식 표준으로 제안하는 작업이 이루어졌다.
그런 과정들을 거쳐 2009년에 유니코드 5.2이 공표됨으로써 첫가끝 조합형을 표준화하는 작업이 마무리되었다. 애써 마련한 표준이 실효성을 띠게 하는 일은 21세기 세종계획에 참여한 기업들의 힘으로 이루어졌다. 마이크로소프트와 한글과컴퓨터를 비롯한 프로그램 개발 업체들은 2010년대에 유니코드에 들어간 내용을 근거로 하여 첫가끝 조합형을 지원하는 입력 도구와 글꼴 등을 만드는 작업을 벌여 나갔다. 한글과컴퓨터가 가장 발빠르게 'ᄒᆞᆫ글 2010'부터 옛한글 표현 방법을 한양 PUA 완성형이 아닌 유니코드의 첫가끝 조합형으로 바꾸었고, 마이크로소프트는 '윈도우 8'부터 'Microsoft 옛한글' 입력기와 '맑은고딕' 글꼴을 통하여 첫가끝 조합형을 쓰는 옛한글 입출력 기능을 운영체제 차원에서 지원하고 있다.
유니코드 완성형 부호계와 마찬가지로 첫가끝 부호계도 마이크로소프트의 움직임이 다른 운영체제들과 응용 프로그램들에까지 널리 자리잡는 데에 영향을 미쳤다. 안드로이드(Android)와 우분투(Ubuntu)를 비롯한 리눅스 계열 운영체제들도 차츰 판올림하면서 유니코드에서 갱신된 내용을 반영해 나갔고, 유니코드에 들어간 첫가끝 조합형에 대해서도 프로그램 지원을 늘려 나갔다.
첫가끝 부호계는 3벌식 부호계이므로, 3벌식 자판과 가장 짝이 맞는 부호계이다. 첫가끝 조합형을 연구하거나 표준화하는 일에 참여한 사람들은 세벌식 자판에 관심을 두고 있던 비율이 높았다. 그러나 정작 21세기 세종계획을 거치면서 주류로 자리를 굳힌 옛한글 자판은 세벌식이 아니라 두벌식이었다.
KS X 5002에 바탕한 표준 두벌식 자판에 옛낱자를 더 넣은 두벌식 옛한글 자판은 1980년대부터 쓰이고 있었다. 21세기 세종계획 초기에 두벌식 옛한글 자판은 유니코드의 채움 문자(첫소리 채움 문자, 가운뎃소리 채움 문자)가 더 들어갔다. 이 두벌식 옛한글 자판이 훈민정음(삼성전자)과 MS 워드(마이크로소프트), ᄒᆞᆫ글 워디안(한글과컴퓨터)에서 구현되어 옛한글 분야의 연구 사업(옛 문헌의 한글 내용 넣기, 말뭉치 자료기지 구축 등)에 쓰였다. 1990년대 후반까지 틀이 잡힌 두벌식 옛한글 자판은 그 뒤에 여러 환경에서 가장 흔히 쓰이는 옛한글 자판으로 이어졌다.주16 이 덕분에 웹(web)에서도 두벌식 자판으로 미완성 한글과 옛한글을 바로 넣을 수 있는 기반이 닦여 있다.

• 그림 12-17, 12-18 실린 곳 : [온라인 한글 입력기] 두벌식 옛한글 자판 (https://pat.im/1179)
• 온라인 한글 입력기 : http://ohi.pat.im/?ko=2-KSX5002&y=1
1980~1990년대 이전의 문자 부호계 표준화 작업들은 몇몇 전문가들이 짧게 모인 비공개 논의로 결론을 내는 때가 많았다. 그렇게 제정된 'KS 완성형'(KS C 5601)과 같은 표준 부호계는 '설믜'나 '똠방' 같은 말을 처리하지 못하여 크고 작은 사고를 일으키기도 했다. 그래서 출판업계와 국어학계에서는 정보통신 업계의 요구가 많이 반영된 표준 부호계보다 자신들의 요구가 더 잘 반영된 비표준 부호계를 쓰는 때가 잦았다. 표준 제정 과정에서 뒷날에 좋은 쪽으로 본받을 점이 적었고, 그렇게 나온 표준 부호계는 표준이면서도 시장을 통일하지 못하여 다른 비표준 부호계들의 도전을 받았다.
21세기 세종 계획으로 표준화 작업이 마무리된 '첫가끝 조합형'은 보기 드문 사례였다. 첫가끝 부호계는 유니코드 1.1에 갑자기 들어갔지만, 후속 보완 작업은 길면서 철저했다. 국어학계가 주도하여 문헌 조사를 통하여 필요한 옛낱자를 추리는 작업을 이어 나갔고, 최종 결과물을 마련하기까지 학계/기관/업계의 전문가들이 시간을 두고 토론에 참여하여 내용을 검토하여 고쳐 나갔다. 그래서 착오는 겪었더라도 KS 완성형이나 유니코드 1.1의 완성형 부호계에서 겪은 매우 나쁜 결과는 피할 수 있었다. 어느 한쪽의 입장에 너무 기울지 않고 학계와 업계를 아우르는 다양한 주체들의 의견과 정보를 폭넓게 모으려 한 과정이 좋은 본보기가 될 수 있는 국책 연구 사업이었다.
21세기 세종계획은 특히 옛한글 쪽에서 두드러진 성과를 냈고, 유니코드의 한·중·일 통합 한자(CJK Unified Ideographs) 영역에 한국 한자를 넣는 일에도 관여했다. 하지만 넓게 관여한 연구 분야들 가운데는 아쉬움을 남긴 분야도 있다.
한문에 토를 달 때 쓰는 구결(口訣) 문자도 21세기 세종계획에서 다룬 대상이었지만, 유니코드에 구결 문자를 따로 올리지 못하여 유니코드 사용자 정의 영역(PUA)의 부호값으로 나타내거나 꼴이 같은 한자를 써서 구결을 나타내고 있다. 구결은 한자를 본떠 만들어졌지만, 뜻이나 목적은 글씨꼴이 같은 한자와 다르다. 그래서 구결이 한자와 다른 부호값으로 들어가면, 구결이 들어가는 글 내용이 한자와 마구 뒤섞이지 않아서 찾기 편할 수 있다.
한글 낱자인 아래아(ㆍ)로 나타내는 때가 많은 '넓은 가운뎃점'도 한글 문화권의 출판물에 많이 쓰이는 기호인데, 21세기 세종계획에서 깊이 다루어질 기회를 잡지 못했다. 가운뎃점은 유니코드 부호값 U+00B7를 쓰는 ·로 많이 나타내지만, 이 부호는 많은 글꼴들에서 로마 문자에 알맞은 폭과 굵기로 나오므로 한글이 주로 들어가는 글에서 쓰기에는 너무 얇고 좁다. 그래서 국회 회의록과 국립국어원의 웹 문서들만 보아도 가운뎃점을 꼴이 비슷해 보이는 '호환용 한글 자모'의 아래아(ㆍ, U+3130)로 나타내는 모습을 흔히 볼 수 있다. 한글 낱자인 아래아(ㆍ)는 문장 부호로 쓰기 위한 기호가 아니고, 아래아로 가운뎃점을 나타내면 아래아를 기호로 쓴 것인지 한글 낱자로 쓴 것인지를 가리기 어렵게 된다. 일본 문자에도 카타카나 가운뎃점(・, U+30FB)이 따로 있는 것을 헤아려 보면,주17 한글 문서에서 자주 쓰이는 기호를 가리키는 부호값을 따로 마련하지 않고 사람들이 알아서 쓰도록 내맡기고 있는 것은 너무 아쉬운 대목이다.
21세기 세종계획이 활발한 활동을 끝낸 뒤에도 필요는 있지만 비표준에 머물고 있는 문자들이 아직 있다. 이 문자들을 표준 부호계에 올리거나 글꼴 처리로 알맞게 나타내는 일이 숙제로 남아 있다.
▣ 첫가끝 조합형의 이상과 현실
첫가끝 조합형은 한글을 나타내는 폭이 가장 넓은 한글 조합 방안이지만, 그럼에도 오늘날에 첫가끝 조합형은 완성형으로 나타내지 못하는 한글(미완성 한글, 옛한글 등)을 나타낼 때에만 쓰이는 때가 많다. 유니코드로 한글을 나타내는 방법이 완성형 방식과 조합형 방식으로 나뉜 것과 첫가끝 조합형이 완성형의 보조 방안처럼 쓰이는 것은 미리 기획한 결과가 아니다. 당장 쓰기 편한 방식(완성형 방식)을 따르려는 입장과 되도록 한글 처리가 간단한 방법으로 한글을 나타내려는 방법을 쓰려는 입장과 한글을 나타내는 폭을 넓히려는 입장이 서로 어긋나기도 하고 타협하기도 하면서 절충된 결과이다.
한글을 나타내는 방안이 완성형과 조합형으로 나뉜 것 때문에, 한글을 조합해 나가는 방법과 낱내자를 마무리하여 부호값을 매기는 방법도 나뉘게 된다. 그래서 한글을 조합하는 방법도 여러 가지가 나올 수 있다.
- 한글을 조합할 때
- 첫가끝 낱자부터 쓸지
- 호환용 한글 자모부터 쓸지주18
- 낱내자로 나타낼 때
- 완성형으로 나타낼 수 있는 낱내자를 완성형으로 나타낼지
- 모든 낱내자를 첫가끝 조합형으로 나타낼지


위의 움직그림들에서 보면 'ᄇᆞᆯ'처럼 아래아(ㆍ)가 들어가는 낱내자들은 첫가끝 조합형으로 나타낼 수밖에 없지만, '래'는 완성형 부호값(U+B798)으로도 나타낼 수 있고 조합형 부호값(U+1105, U+1162)으로도 나타낼 수 있다.
그림 13-10은 첫가끝 조합형으로만 조합하는 방식이다.
그림 13-11는 조합할 때는 첫가끝 조합형으로 넣되 조합이 끝나면 완성형으로 나타낼 수 있는 낱내자를 완성형 부호값으로 바꾸는 방식이다.
그림 13-12은 호환 자모로 조합을 시작하고 조합이 끝난 낱내자를 되도록 완성형 부호값으로 바꾸되, 호환 자모나 완성형 부호값으로 나타낼 수 없을 때에만 첫가끝 조합형으로 나타내는 방식이다. ('ㅏ+ㅏ→ㆍ'로 바꾸는 낱자 조합 규칙이 예외로 더하여 쓰였다.)


그림 13-13은 2019년 현재 윈도우 10에서 'Microsoft 옛한글' 입력기로 'ᄇᆞᆯᄀᆞᆫᄃᆞ래'를 넣고 뒷걸음쇠로 지울 때의 모습이다. Microsoft 옛한글 입력기는 첫닿소리와 끝닿소리를 가려 나타내려고 호환 자모를 쓰지 않지만, 조합 단계부터 완성형 부호값을 우선하여 쓴다. 그런데 뒷걸음쇠로 지울 때에 'ᄇᆞᆯ'이 낱자 하나씩 지워지면서 'ᄇᅠ'이 채움 문자(U+1160) 없이 첫소리 ㅂ을 가리키는 U+1107만 남는 때가 생긴다. 이렇게 가운뎃소리 채움 문자(U+1160) 없이 첫소리 낱자 하나만 남는 것은 그림 13-7에서 본 유니코드 표준과 KS X 1026-1에 나오는 첫가끝 조합형 운용 원칙에 어긋난다.
가장 간편한 한글 조합 방식은 그림 13-10처럼 처음부터 끝까지 첫가끝 조합형만 조합하는 방식이다. 그러나 첫가끝 조합형은 표준 방식이면서도 주로 쓰이는 표준은 아니다. 2007년에 제정된 국내 표준인 KS X 1026-1(정보교환용 한글 처리 지침)에는 여러 유형의 한글을 부호값으로 처리하는 세세한 방법들이 실려 있는데, KS X 1026-1에서는 완성형으로 나타낼 수 있는 글자마디(낱내자)는 완성형으로 나타내고 그럴 수 없는 한글을 첫가끝 조합형으로 나타내게 하였다.
완성형을 주로 쓰게 한 KS X 1026-1을 곧이곧대로 따르지 않더라도, 오늘날의 현실에서 첫가끝 조합형만 쓰기는 쉽지 않다. 첫가끝 조합형을 쓸 때에 이런 문제들을 겪을 수 있기 때문이다.
- 뒷걸음쇠(백스페이스)로 지울 때에 낱내자 단위가 아니라 낱자 단위로 지워짐주19
→ 한글을 지우는 시간이 오래 걸림 - 낱자 단위로 지워질 때에 채움 문자가 찌꺼기로 남기도 함주20
→ 찌꺼기로 남은 채움 문자 때문에 눈에 보이는 것과 다른 내용으로 처리될 수 있음 - 첫가끝 조합형을 지원하는 한글 글꼴이 없거나 쓸 수 없는 때에 한글 낱자들이 풀려 나옴
애플의 맥 OS(OS X)에서 쓰이는 HFS+ 파일 시스템에서는 한글이 들어가는 파일 이름을 유니코드 정규화 C(NFC)가 아닌 유니코드 정규화 D(NFD)를 써서 넣는다. 그래서 맥 OS에서 첫가끝 방식으로 들어간 한글 파일 이름은 첫가끝 조합형을 지원하는 글꼴을 갖추지 못한 다른 운영체제들에서 낱자 단위로 풀려 보일 수 있다. 이를테면 '글걸이.txt'가 'ㄱㅡㄹㄱㅓㄹㅇㅣ.txt'와 비슷한 꼴로 보일 수 있다. 한글을 나타내는 부호값이 서로 다르면 같은 한글 내용이 다른 내용처럼 취급되기도 하고, 가나다 차례짓기도 더 까다롭다.
그 동안 전산 기기에서는 완성형 부호계가 주로 쓰여 와서, 한글을 써 온 사람들도 완성형 부호계의 특성에 익숙해져 있다. 한글을 낱내자 단위로 지우는 것은 첫가끝 조합형을 쓰는 때에도 당연히 바랄 수 있는 기능이다. 하지만 첫가끝 조합형은 아직도 프로그램에 따라 글을 넣거나 지울 때의 문자 처리가 조금씩 다르게 구현되기도 하는 형편이다. 'ᄒᆞᆫ글'이나 '날개셋 편집기'처럼 첫가끝 조합형을 세밀하게 구현하는 프로그램도 있지만, 다른 입력 프로그램들에서는 채움 문자나 방점 등에서 부호값 처리의 세밀함이 떨어지는 때가 종종 있다. 부호값 처리가 잘 되더라도 알맞은 글꼴이 없어서 첫가끝 조합형으로 넣은 한글을 바른 모습으로 볼 수 없는 때도 있다. 이런 문제들은 운영체제 차원에서 개선되면 효과가 매우 크지만, 모든 문제들이 금방 다 풀리기는 어려워 보인다. 그래서 그림 13-11 ~ 13-13처럼 그 동안 완성형 부호계를 주로 써 온 관행에 순응하여 옛한글을 넣는 때에도 되도록 완성형 부호값을 쓰는 방법이 당장의 낯섦과 불편함을 피하는 길이 되고 있다.
이처럼 첫가끝 조합형이 완성형 방식의 보조 방안처럼 쓰이는 것은 첫가끝 조합형의 기틀을 잡은 사람들이 처음에 바랐던 모습이 아니다. 초창기에 첫가끝 조합형을 고안했던 사람들은 한 가지 한글 부호계로 모든 한글을 나타내는 것을 목표나 이상으로 삼았고, 성격이 다른 부호계를 두 가지 이상 섞어 쓰는 것을 처음부터 헤아리지는 않았다. 이에 얽힌 이야기들을 이어지는 글에서 다루려고 한다.
참고한 자료
- 신병훈 · 김성재 · 안상규 (마이크로소프트 개발부), 「마이크로소프트 Word 2002에서의 옛한글 구현」, 국립국어연구원, 〈국어 연구 자료 구축 1〉, 2002.12.30.
- 산업자원부 기술표준원, 〈정보기술―국제문자부호계(UCS)―한글―제1부 : 정보교환용 한글 처리 지침〉(KS X 1026-1 : 2007), 한국표준협회 (2007.12.31 제정)
- 양왕성, 「옛한글 코드의 변천사」, 《정신문화연구》 제41권 제4호(통권 제153호), 2018.12.10.
- 21세기 세종 계획
- 고려대학교 민족문화연구원 비표준문자등록센터 (연구책임자:정우봉), 〈비표준문자등록센터 사업 보고서〉, 문화관광부, 1999.11.
- 고려대학교 민족문화연구원 비표준문자등록센터, 〈비표준문자등록센터 사업 보고서〉, 문화관광부, 2000.12.
- 문화관광부·국립국어원(연구책임자:박병천), 〈옛 문헌 한글 글꼴 발굴·복원 연구 -17,18세기 문헌을 중심으로-〉, 문화관광부, 2002.11.
- 문화관광부·국립국어원(연구책임자:박병천), 〈옛 문헌 한글 글꼴 발굴·복원 연구 -19,20세기 문헌을 중심으로-〉, 문화관광부, 2003.11.
- 정우봉·김흥규·권순회·박종우·신상현, 〈연구보고서 【2004년】 ― 21세기 세종계획 문자코드 표준화 연구〉, 문화관광부, 2014.12.10.
- 정우봉·박종우·신상현 등, 〈연구보고서 【2006년】 ― 21세기 세종계획 문자코드 표준화 연구〉, 국립국어원, 2006.12.20.
- 「옛한글정보처리연구위원회 회의 개최」, 고려대 민족문화연구원 문자코드연구센터, 《문자코드연구센터 소식》 제18호, 2006.12.30.
- 김흥규, 「옛한글 표준화 과정과 의의」, 고려대 민족문화연구원 문자코드연구센터, 《문자코드연구센터 소식》 제19호, 2007.7.31.
- 정우봉·박종우·신상현 등, 〈연구보고서 【2007년】 ― 21세기 세종계획 문자코드 표준화 연구〉, 국립국어원, 2007.12.10.
- 국립국어원, 〈21세기 세종계획 백서〉, 국립국어원, 2007.12.11.
- 유니코드
- The Unicode Standard, Version 4.1 - Archived Code Charts : https://www.unicode.org/Public/4.1.0/charts/CodeCharts.pdf
- The Unicode Standard, Version 5.2 - Archived Code Charts : ftp://ftp.unicode.org/Public/5.2.0/charts/CodeCharts-noHan.pdf
- The Unicode Consortium, 〈The Unicode Standard Version 5.2〉, 2009.12.9., https://www.unicode.org/versions/components-5.2.0.html
- ISO/IEC JTC1/SC2/WG2 N3242, L2/07-103, 2007.4.16., http://std.dkuug.dk/jtc1/sc2/wg2/docs/n3242.pdf
- Unicode Character Encoding Stability Policies : https://www.unicode.org/policies/stability_policy.html
- FAQ - Korean : https://www.unicode.org/faq/korean.html
- 위키백과
- 나무위키
- 조합형 : https://namu.wiki/w/조합형
- HFS+ : https://namu.wiki/w/HFS+
- 문자 집합 위키
- 한양 PUA : https://charset.fandom.com/ko/wiki/한양_PUA
- 유니코드 1.1 옛한글 506051자 : https://charset.fandom.com/ko/wiki/유니코드_1.1_옛한글_506051자
- 유니코드 옛한글 1638750자 : https://charset.fandom.com/ko/wiki/유니코드_옛한글_1638750자
- 글걸이
- [온라인 한글 입력기] 두벌식 옛한글 자판 (https://pat.im/1179)




![미리보기 그림 - [온라인 한글 입력기] 보태고 고친 풀어쓰기 기능](/thumbnail/1/JP_Thumb/coverphoto/thumb_1702892062.gif.webp)
덧글을 달아 주세요
전마머꼬 2020/02/04 16:08 고유주소 고치기 답하기
ᄓᅶᇃ 유니코드 입력으로 써봤는데 신기하네요. 지워지기도 끝부터 지워지고 ...
그런데 이 글자가 utf-16에서 6바이트나 한다는거고... 표준위원회에서
안 받아줘서 bmp영역 안들어갔으면 12바이트나 했겠습니다.
아이구 무서워라...
NFC, NFD는 뭐 어떻게 처리되고 있는지는 모르겠지만...
대단한 노력입니다.
조선 문헌들에서 새로운 자소(?) 계속나온다니 노고가 보통이 아니군요...
조합형이라는게 capacity 에서는 손해를 마ㄶ이 보는 것 같은데... 표현력만으로도
큰 가치가 있네요.
팥알 2020/02/04 19:42 고유주소 고치기 답하기
표준화라는 게 얼마나 대단하고 편리할 수 있는지가 예로 들어주신 유니코드 옛한글을 다루어 보면 잘 드러납니다.
조합형만 쓴다고 하면 요즘한글과 같은 표현 방법으로 나타낼 수 있어서 좋습니다.
조합용 한글 낱자들이 유니코드의 노른자인 BMP 영역에 들어간 것도 국내외의 많은 분들이 힘 쓰고 도와 주신 결과이기도 합니다.
프로그램과 글꼴을 개발하여 표준이 명목에만 머무르지 않고 실효성을 띨 수 있게 해 준 분들의 노고도 잊지 말아야 하겠고요.
국책 사업으로 진행된 문헌 연구가 일단락되고 유니코드에 반영된 덕분에 이제는 못 나타낼 한글이 거의 없게 되었습니다. 하지만 만약에 더 넣어야 할 낱자가 나온다면 머리 아플 것 같습니다. 옛낱자들 가운데는 심하면 문헌에 한두 번 쓰이고 만 것도 있고,정식 낱자로 인정 받지 못하고 탈락한 것도 있었다고 합니다. 나중에 비슷한 낱자가 또 많이 발견된다면, 그 때는 BMP에 넣는 걸 고집하기가 쉽지 않겠죠.
진현수 2021/10/16 18:59 고유주소 고치기 답하기
저는 오리지날 28자 훈민정음을 모두 사용할 수 있는 함초롬체를 즐겨 사용하고 있습니다. 중국 노래나 샹송 등 한글로 발음을 적기 어려운 가사를 표기할때 쓰고. 다만 아이폰이나 남에게 보여줄때 함초롬체가 깨져나오는 경우가 많아 왜 그런지 검색을 하다가 이런 한글을 전산화하는데 이런 엄청난 역사가 있었다는 것을 알게 되었네요.
알파벳 26자, 훈민정음28자인데. 알파벳도 1자로 표기하지 못하는 자음을 th ch wh gn식으로 하듯 훈민정음도 병서연서를 사용할 수 있지만. 중세에 원칙없이 너무 다양한 조합이 쓰여 혼란속에 사라진 것 같습니다. 윗글에서도 결국 초성에 자음2개 콤비, 종성에 자음2개 콤비하다 보니 총 5자리를 곱하다 보니 애로가 꽃피네요.
중세국어 문헌에 사용례가 있다한들. 세종이나 신숙주 수준이 아니면 훈민정음의 근본원칙을 이해하고 병서/연서/모음조합 등을 사용한 경우가 얼마나 될지 의문입니다. 조선어학회가 빼버린 ㆆ에서 윗쪽 작대기가 혀밑(설저)이고, '으'의 작대기가 입천장을 지칭한다는 것을 누가 알까요. ㆆ가 있어야 영어교사들이 그토록 원하는 low level vowel(혀위치가 낮은 상태로 발음되는 ʌ æ 등)을 표기할 수 있는데.
함초롬체도 초중종 성이 조합되었을때 각글자들이 그닥 미려하진 않은데. 상세하게 설명해주신 한글이 컴퓨터에 들어가 구현되는 원리의 역사를 보니. 한정된 초성병서조합+음은 음끼리 양은 양끼리 꼭 짝을 맞추지 않는 자유로운 모음조합(ex ㅗ+ㅓ) 2가지만 조합형으로 만족시키려 해도 구현하려면 많은 애로가 있겠네요. 소리글자는 알파벳이 너무 많아도 좋은 건 아니고. 라틴알파벳 26개에 비해 움라우트 같은거 없이 28자로 만들어주셨으면 세종대왕님은 정말 잘 뽑아내신 건데. KS운운하는 공무원들 만나서 훈민정음이 신세를 망쳤네요.
팥알 2021/10/20 11:39 고유주소 고치기 답하기
도움말씀 고맙습니다.
닿소리 ㅇ(이응)이 빈 소리로 쓰이기도 하고 ㆁ으로 쓰이기도 하는 것처럼 요즘한글에서도 모습이 같은 낱자가 때에 따라 다르게 쓰이는 모습을 볼 수 있습니다. '옛한글'이라고 불리는 한글 영역에서는 관점이 여러 갈래로 나뉘어 있는 경우가 많던데, 그 점이 어렵기도 하고 흥미롭기도 합니다.
아무리 나타내는 폭이 넓은 한글 전산 표현 방식이 있어도 널리 쓰일 수 있으려면 꾸준히 프로그램을 만들고 다듬어서 보급하는 정성이 필요합니다. 그 동안 여러 기업체들과 개발자들이 힘을 기울인 덕분에 요즈음에 함초롬체 등을 통하여 첫가끝 조합형을 널리 쓸 수는 있지만, 표준어에서 벗어나는 말을 나타내는 것에 사람들의 관심이 적기 때문인지 아쉬운 점이 빨리 풀리지 않고 있는 모습을 더러 봅니다.
21세기 세종 계획 등에서 이루어진 문헌 조사는 전산 환경에서의 한글 표현 방안을 표준화하는 일에서 꼭 필요한 일이었습니다. 일제 강점기나 6·25 동란 같은 어려운 때가 없었다면 더 일찍 대규모 문헌 조사를 벌여 관련 연구자들의 한글에 관한 지식 수준을 높힐 수 있었겠지만, 그런 쪽에서 준비 작업이 늦는 바람에 한글 표현 방안을 일관성 있게 마련하지 못하고 완성형과 조합형을 함께 쓰게 되었다고 생각합니다.
유니코드와 한국산업표준으로 확정된 첫가끝 조합 방안도 한글을 나타내는 폭은 아쉬움이 있습니다. 유니코드에 올리지 않은 겹낱자를 조합하는 방안이 없어서 나중에 옛 문헌에서 겹낱자가 더 발견되면 유니코드에 겹낱자를 더 넣어야 할 수 있습니다.
하지만 부호계와 글꼴을 운용하는 편의를 높이고 활용 폭을 넓히는 쪽으로 발전시키는 일도 중요합니다. 오직 한글을 나타내는 폭을 넓히려고만 했으면 첫가끝 조합형도 N 바이트 조합형처럼 개발자들이 아주 등을 돌리는 한글 표현 방식이 되었을지 모릅니다. 오늘날에 쓰이는 첫가끝 조합형은 그럭저럭 운용 편의와 표현 폭이 잘 절충된 꼴인 것 같습니다.
조원철 2022/01/19 11:15 고유주소 고치기 답하기
제목 : 외국어(F, V, TH)의 한글 표기
목적(효과) :
외국어(F, V, TH)의 보다 정확한 한글 표기
한글(문자)의 국제화
내용 :
외국어(영어 기준)의 F, V, TH 의 발음을 한글로 구분되게 보다 정확하게 표기
예 :
F : ㅍ → ㅍ+∘ ⇨
V : ㅂ → ㅂ+∘ ⇨
TH : ㅅ/ㄷ → ㅅ/ㄷ ⇨ /
처럼 하게하는 키보드의 조합은 불가능한가?
아니면
자판에 하나 더
아니면
문자 판에 아예 고정 시키든지요
팥알 2022/01/20 20:56 고유주소 고치기 답하기
글쇠 조합을 하거나 자판 배열을 바꾸어서 V나 F에 대응하는 한글 낱자를 나타내게 할 수 있습니다.
다만 그렇게 넣는 한글 낱자를 널리 쓰려면 그 낱자를 어떤 부호값으로 어떻게 나타낼지를 미리 약속을 해 둘 필요가 있습니다. 그 낱자들을 유니코드에 이미 들어간 낱자들(ᅋᅠ, ㆄ 따위)의 부호값으로 나타낼 수도 있고, 유니코드에 새로운 낱자들을 넣는 길도 있습니다. 자판 배열에 조합용 부호( https://pat.im/1185 에 나오는 이음 문자 같은 부류 )를 따로 두어서 기초 낱자와 조합해 넣게 수도 있을 겁니다. 자판 배열에 V나 F를 나타내는 낱자를 따로 넣는 것도 생각할 수 있습니다.
여러 가지 방법이 나올 수 있습니다. 적은 글쇠로 한글을 넣는 자판 배열을 목표로 할 수도 있고, 글쇠를 많이 쓰더라도 단순한 방법으로 낱자를 넣는 자판 배열을 만들 수도 있습니다. 여러 가지 방법들에 모두 장단점이 있습니다.