[PHP] 유니코드 정규화 함수 Normalizer::normalize
Normalizer::normalize 함수는 문자열을 받아 유니코드 정규화 형식으로 바꾼 문자열을 돌려준다. 오류가 생기면 거짓(false) 값을 돌려준다.
php-intl 모듈이 깔려 있어야 쓸 수 있다. normalizer_normalize도 같은 함수이다.
▣ 형식
public static Normalizer::normalize(string $string, int $form = Normalizer::FORM_C): string|false
normalizer_normalize(string $string, int $form = Normalizer::FORM_C): string|false- $form 자리에 넣을 수 있는 상수값 (int)
- Normalizer::FORM_C
- Normalization Form C (NFC) - Normalizer::FORM_D
- Normalization Form D (NFD) - Normalizer::FORM_KC
- Normalization Form KC (NFKC) - Normalizer::FORM_KD
- Normalization Form KD (NFKD)
- Normalizer::FORM_C
- $form 자리에 따로 값을 넣지 않으면 기본값은 Normalizer::FORM_C임
▣ 보기
$original_content = "한글이름.note";
if(method_exists('normalizer','normalize')) {
$content = normalizer::normalize($original_content);
print('default : '); var_dump($content); print('<br />');
$content = normalizer::normalize($original_content, Normalizer::FORM_C);
print('NFC : '); var_dump($content); print('<br />');
$content = normalizer::normalize($original_content, Normalizer::FORM_D);
print('NFD : '); var_dump($content); print('<br />');
}▣ 출력 결과
default : string(17) "한글이름.note"
NFC : string(17) "한글이름.note"
NFD : string(38) "한글이름.note"
php-intl 모듈이 깔려 있지 않아서 normalizer::normalize를 쓰지 못하는 것에 대비하여, method_exists 함수로 normalizer 클래스에 normalize 메소드(멤버 함수)가 있는지 알아보는 조건문을 달아둘 수 있다.
Normalizer::FORM_C를 생략한 normalizer::normalize($original_content)의 수행 결과는 normalizer::normalize($original_content, Normalizer::FORM_C)와 같다.
$original_content에 들어간 "한글이름"은 맥 OS에서 들어가는 한글 파일 이름처럼 첫가끝 낱자들로 이루어진 NFD 형식 한글이다. 이를 NFC 형식으로 정규화하면 낱자가 아닌 낱내자(음절자) 단위로 부호값이 매겨진다. var_dump로 알 수 있는 NFC 한글과 NFD 한글의 문자열 길이가 다르다. 위의 출력 결과를 다른 곳에 복사해서 글꼴을 바꾸어 보고 뒷걸음쇠(백스페이스)로 지우거나 커서를 옮겨 보면 다른 특성이 보일 수 있다.
$original_content = "나랏〮말〯ᄊᆞ미〮 듀ᇰ귁〮(中國)에〮 달아〮";
이와 같은 옛한글은 normalizer::normalize 함수로 유니코드 NFC 정규화를 할 수 없다. 옛이응(ㆁ)이 들어간 '듀ᇰ'(ᄃᅠ+ᅟᅲ+ᅟᅠᇰ )은 NFD로만 나타낼 수 있고 NFC로는 나타낼 수 없다. 이를 억지로 NFC로 바꾸면. '듀'만 NFC 형식으로 바뀌고 받침 옛이응은 NFD 형식으로 남아서 '듀 + ᅟᅠᇰᅟ'이 된다. 운 좋게 글꼴 처리가 잘 되어 NFC로 바뀐 글 내용이 본래 내용과 비슷하게 보이는 때는 있지만, 속 내용을 일관성 없게 바꾸는 정규화는 뜻이 없다.
default : string(64) "나랏〮말〯ᄊᆞ미〮 듀ᇰ귁〮(中國)에〮 달아〮"
NFC : string(64) "나랏〮말〯ᄊᆞ미〮 듀ᇰ귁〮(中國)에〮 달아〮"
NFD : string(103) "나랏〮말〯ᄊᆞ미〮 듀ᇰ귁〮(中國)에〮 달아〮"

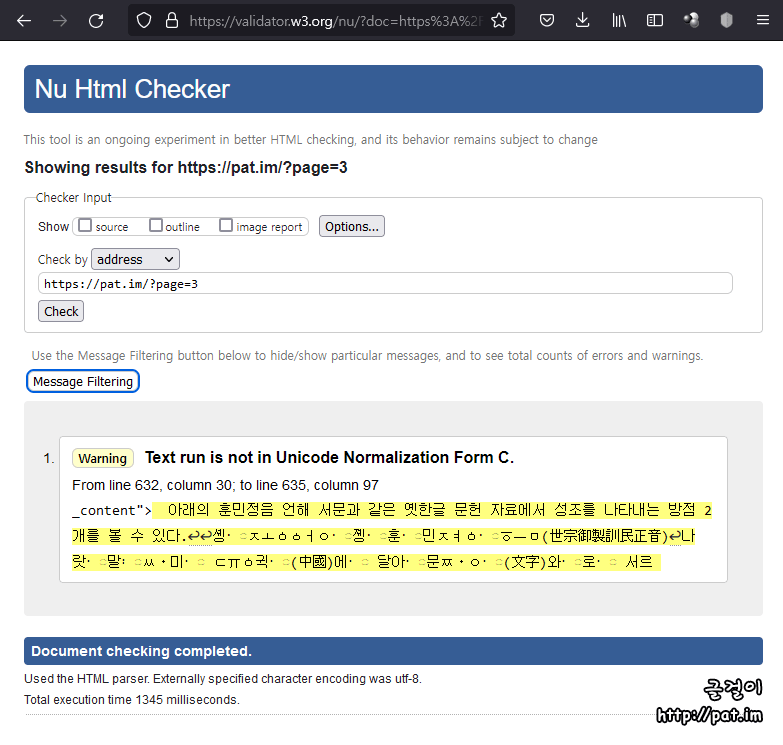
옛한글이 들어간 HTML 문서를 W3C 웹 표준 검사기에 넣으면 위와 같이 "Text run is not in Unicode Normalization From C."이라는 경고문이 뜬다. normalizer::normalize 함수로 NFC 방식으로 바꾸면, 이 경고문은 사라지지만 옛한글 내용이 달라진다. 옛한글 내용을 바르게 지키면서 이 경고문을 없앨 방법은 아직 없으므로, NFC로 바꾸라는 위 경고문은 현재의 실정에 맞지 않다고 보고 가볍게 넘기는 것이 좋다.
그렇지만 normalizer::normalize 함수를 통한 유니코드 NFD 정규화는 한글을 일관성 있게 다루는 데에 도움이 될 수 있다. 한글을 주로 낱내자 단위(완성형, NFC 방식)으로 나타내되 어쩔 수 없는 때에 낱자 단위 표현 방식을 섞는 것이 관행으로 자리잡혔지만, 낱자 단위(조합형, NFD 방식)로만 한글을 나타내는 것이 요즘한글과 옛한글을 가리지 않고 한 가지 방식으로 모든 한글을 나타낼 수 있는 점에서 일관성은 높다.

덧글을 달아 주세요