텍스트큐브에서 에모지(emoji)를 쓸 수 있게 하는 MySQL / MariaDB 설정
유니코드는 다국어 기본 평면(BMP, U+0000~U+FFFF)에 영문이나 한글을 비롯한 오늘날에 자주 쓰이는 문자들이 담겨 있다. 또한 유니코드에는 새 판이 나올 때마다 다국어 보충 문자판(SMP, U+10000~U+1FFFF), 상형 문자 보충 평면(SIP, U+20000~U+2FFFF), 특수 목적 보충 평면(SSP, U+E0000~E0FFF) 등에도 문자들이 더하여 들어가고 있다.
UTF-8 문자 부호화(인코딩) 방식을 따를 때에는 다국어 기본 평면(BMP)에 들어가는 문자는 1~3바이트로 나타내고, 다른 영역에 들어가는 문자는 4바이트로 나타낸다. 에모지(emoji, 이모지, 일본어: 絵文字)라 불리는 이모티콘(emoticon) 구실을 하는 그림 문자들은 다국어 기본 평면(BMP)에도 일부가 들어가지만, 거의 다국어 보충 문자판(SMP)에 들어간다. 고대 문자, 한·중·일 통합 한자, 괄호 문자, 수식 문자 등도 다국어 보충 문자판(SMP)이나 상형 문자 보충 평면(SIP, U+20000 ~ U+2FFFF)에 들어가고 있다.
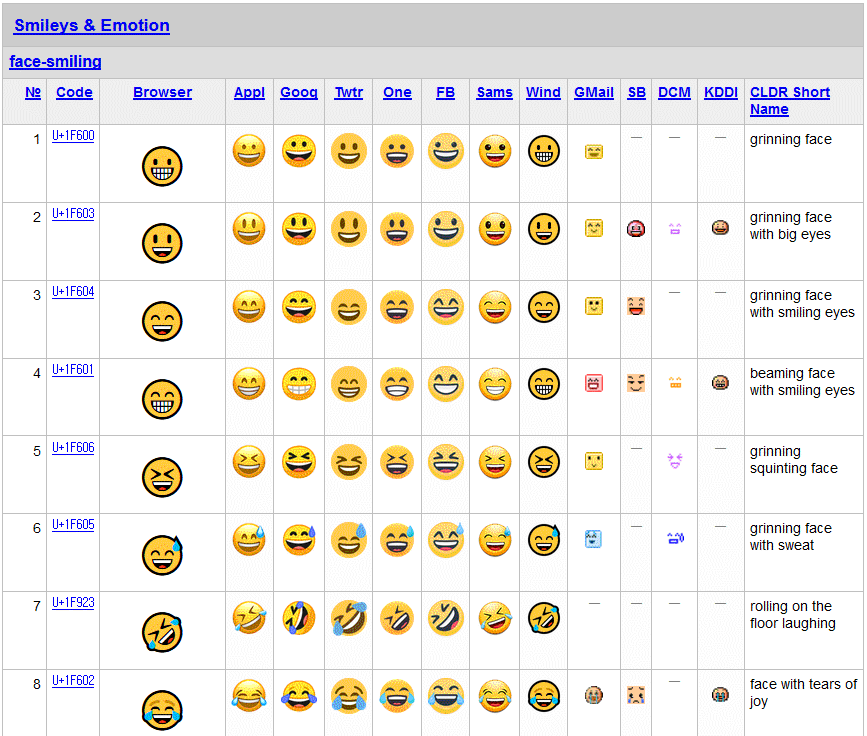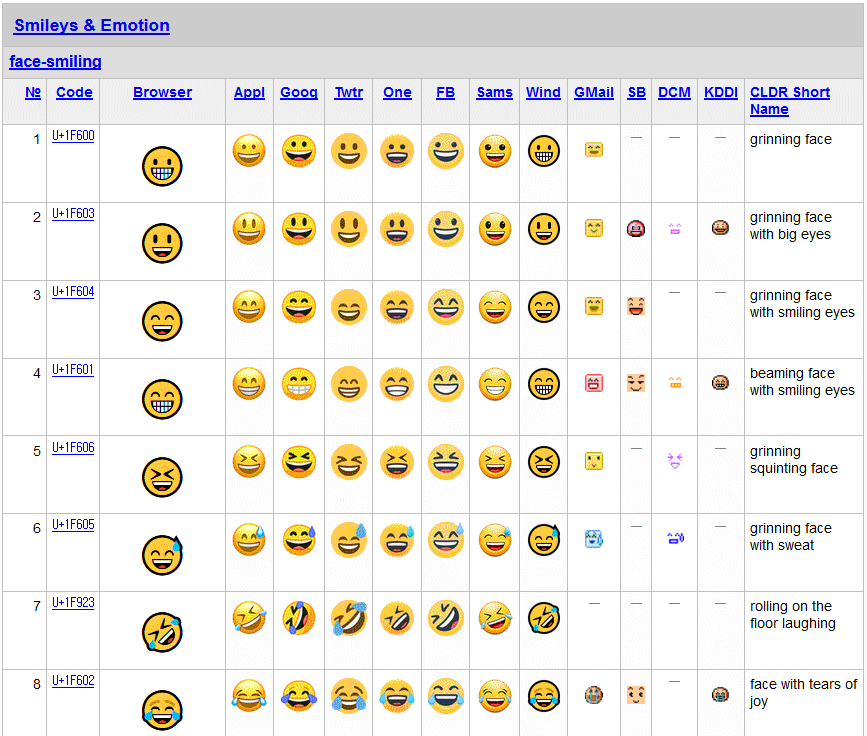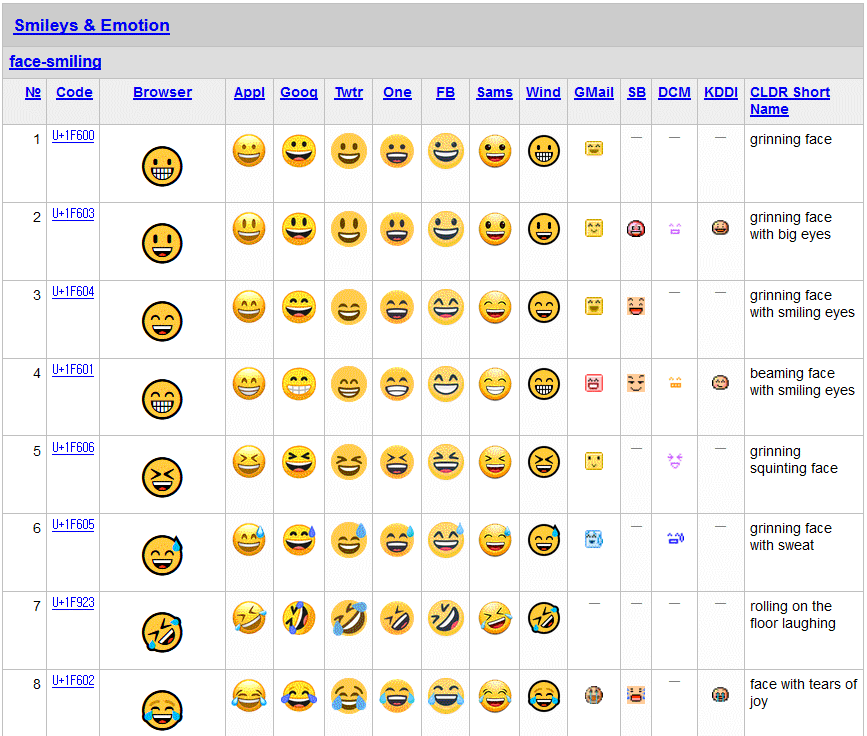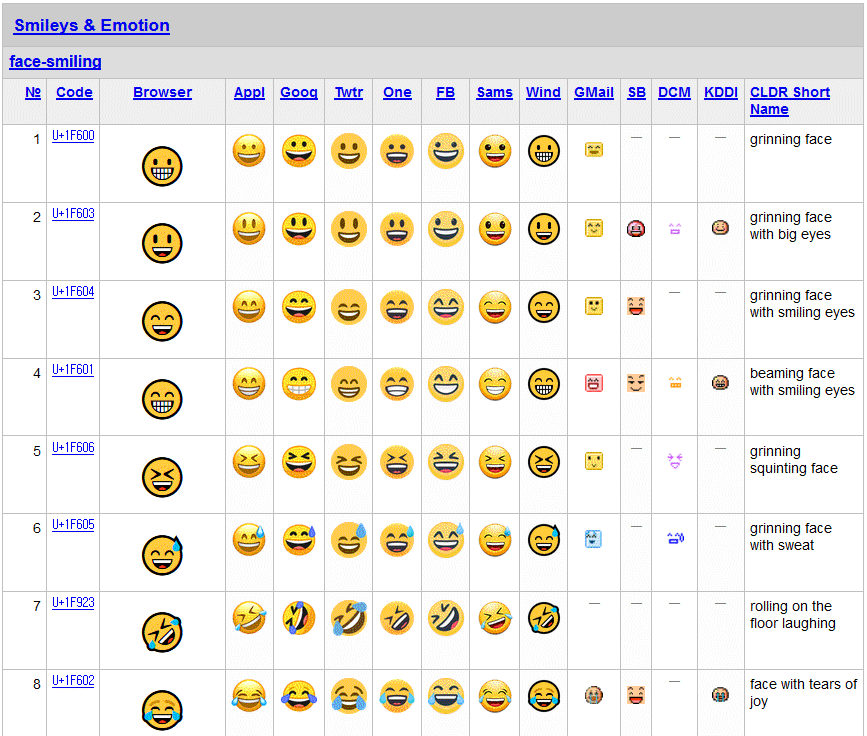
(https://www.unicode.org/emoji/charts/full-emoji-list.html)
텍스트큐브가 자료기지(DB)로 쓰는 MySQL도 UTF-8 부호화 방식으로 유니코드를 지원한다. UTF-8에서는 한 문자의 길이를 1~4바이트로 나타내는데, 4바이트로 나타내는 문자에 에모지 등이 들어간다. 지난날의 MySQL은 UTF-8을 쓰는 자료형을 3바이트까지만 가변 길이로 쓸 수 있게 설계하였다. 이 때문에 예전부터 쓰던 MySQL 자료기지에 4바이트 문자가 낀 자료가 오가면 글이 아예 저장되지 않거나 4바이트 문자들이 빠진 채로 저장될 수 있다.
MySQL에서 'utf8'은 문자당 3바이트 길이까지 처리할 수 있는 UTF-8 문자 집합(character set)을 가리키고, 'utf8mb4'이 문자당 4바이트 길이까지 처리할 수 있는 UTF-8 문자 집합을 가리킨다. MySQL을 쓰는 텍스트큐브에서 에모지를 쓰려면 관련된 프로그램 설정에서 'utf8'을 'utf8mb4'으로 바꾸어 주어야 한다.
텍스트큐브는 아직 이 문제에 대비되어 있지 않아서, 에모지를 비롯한 유니코드에 더 들어가고 있는 많은 문자들을 나타내지 못하는 문제를 안고 있다. 워드프레스 등에서는 자유롭게 쓸 수 있는 문자들을 텍스트큐브에서는 아예 저장도 하지 못하기 때문에 텍스트큐브 블로기의 쓰임새가 제한될 수 있다. 한자나 고대 문자를 다룰 수 없으면 블로그를 학술용으로 쓸 수 없다.
다행히 텍스트큐브도 MySQL의 UTF-8 부호화 방식에 관한 설정을 바꾸면 다국어 기본 평면(BMP)에 없는 유니코드 문자들을 나타내고 기록할 수 있다.
PHP 코드를 고칠 부분은 다음과 같다.▣ /framework/data/MySQLi/Adapter.php 33째 줄
if (self::$db->set_charset("utf8"))
self::$dbProperties['charset'] = 'utf8';
else
self::$dbProperties['charset'] = 'default';
@self::query('SET SESSION collation_connection = \'utf8_general_ci\'');위에서 utf8과 utf8_general_ci을 아래처럼 utf8mb4과 utf8mb4_unicode_ci로 고친다.
if (self::$db->set_charset("utf8mb4"))
self::$dbProperties['charset'] = 'utf8mb4';
else
self::$dbProperties['charset'] = 'default';
@self::query('SET SESSION collation_connection = \'utf8mb4_unicode_ci\'');새로 만들어지는 자료기지에 utf8mb4이 적용되게 하려면 MySQL 또는 MariaDB의 my.cnf에서 다음 항목들을 찾아 고친다.
default-character-set = utf8mb4
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
character_set_server = utf8mb4
collation_server = utf8mb4_unicode_ci
innoDB에서는 찾아보기(인덱스)를 걸 수 있는 문자열의 최대 바이트 수는 767바이트이다. 문자당 3바이트인 utf8일 때에는 VARCHAR의 최대 길이 255일 때에도 '255×3바이트 = 765바이트'로 문제가 없으나, 문자당 4바이트인 utf8mb4에서는 255×4바이트 = 1020바이트'로 767바이트를 넘어서게 되어 문제가 생긴다. 가변 크기 문자열 길이를 VARCHAR(255)에서 VARCHAR(191)로 줄이면 이 문제를 피할 수 있다.
innoDB를 쓰면서 가변 크기 문자열의 길이를 조절하지 않으려면, my.cnf에 다음 내용을 넣어서 찾아보기를 걸 수 있는 문자열 바이트 크기를 늘리는 방법도 있다.
innodb_file_format=barracuda
innodb_large_prefix=on텍스트큐브에서 4비이트로 처리되는 UTF-8 문자열이 들어갈 수 있는 테이블은 Attachments, Comments, Entries, Tags, Users 등이 있다. MySQL 자료기지 전체 또는 에모지 등이 들어갈 수 있는 일부 테이블이나 필드를 utf8mb4으로 바꾸어 준다.
ALTER TABLE `테이블_이름` CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
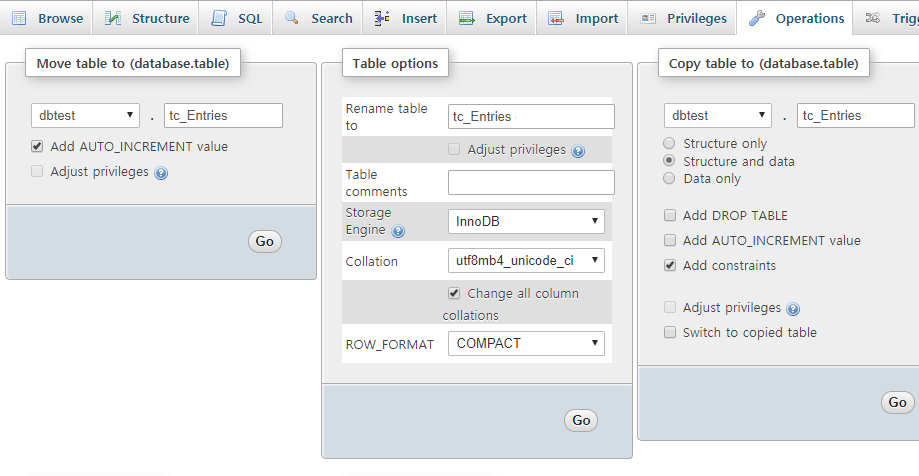
phpMyAdmin을 써서 테이블 단위 또는 필드 단위로 바꿀 수도 있다. 테이블 단위로 바꾼다면, Operation 항목의 'Table option'에서 Collation을 utf8mb4_unicode_ci로 바꾸고 'Change all column collations'에 갈매기표를 한다. 필드 단위로 바꾼다면 Structure에서 변수와 자료형을 골라서 바꿀 수 있다.


기본 상태인 텍스트큐브에서는 아래에 있는 문자들을 글에 저장하지 못하고, 덧글로 넣으면 이 문자들이 빠진 채로 들어간다. 위에서 고치는 작업이 잘 되었다면, 텍스트큐브의 글이나 덧글에 아래 문자들을 붙여 넣어 보면 잘 들어갈 것이다. 다만 쓰고 있는 기기의 운영체제 및 웹 누비개가 지원하는 유니코드 판과 글꼴이 달라서 나타나지 않거나 다르게 보이는 문자가 있을 수 있다. 다국어 기본 평면(BMP)에 들어가지 못한 문자들은 유니코드에 들어간 지 몇 해 되지 않은 것이 많으므로, 최근에 들어간 문자는 운영체제나 글꼴을 최신판으로 판올림해야 보일 수도 있다.
😀 😁 🤪 😂 🤣 😃 😄 😅 😆 😉 😊 😋 😎 😍 😘 😗 😙 😚 🙂 🤗 🤩 🤔 🤨 😐 😑 😶 🙄 😏 😣 😥 😮 🤐 😯 😪 😫 😴 😌 😛 😜 😝 🤤 😒 😓 😔 😕 🙃 🤑 🤕 🤢 🤮 🤧 😇 🤠 🤡 🤥 🤫 🤭 🧐 🤓 😈 👿 👹 👺 💀 👻 👽 🤖 💩 😺 😸 😹 😻
🐶 🐱 🐭 🐹 🐰 🦊 🐻 🐼 🐨 🐯 🦁 🐮 🐷 🐽 🐸 🐵 🙈 🙉 🙊 🐒 🐔 🐧 🐦 🐤 🐣 🐥 🦆 🦅 🦉 🦇 🐺 🐗 🐴 🦄 🐝 🐛 🦋 🐌 🐚 🐞 🐜 🦗 🕷 🕸
👶 👩 🧑 👳 🧕 🧔 👱 👮 👷 💂🏼 🕵🏼 👩🌾 👨🌾 👩🍳 👨🍳 👩🎓 👨🎓 👩🏫 👨🏫 👩🏭 👨🏭 👩💻 👨💻 👩💼 👨💼 👩🔧 👨🔧 👩🔬 👨🔬 👩🎨 👨🎨 👩🚒 👨🚒 👩🚀 👨🚀 👩⚖️ 👨⚖️ 👰 🤵 👸 🤴 🤶 🎅 🧙 🧝 🧛 👼 🤰 🤱 💅
𠀀𠀁𠀂𠀃𠀄𠀅𠀆𠀇𠀈𠀉𠀊𠀋𠀌𠀍𠀎𠀏𠀐𠀑𠀒𠀓𠀔𠀕𠀖𠀗𠀘𠀙𠀚𠀛𠀜𠀝𠀞𠀟𠀠𠀡𠀢𠀣𠀤𠀥𠀦𠀧
🄐🄑🄒🄓🄔🄕🄖🄗🄘🄙🄚🄛🄜🄝🄞🄟🄠🄡🄢🄣🄤🄥🄦🄧🄨🄩🄪🄫🄬🄭🄮🄯 🄰🄱🄲🄳🄴🄵🄶🄷🄸🄹🄺🄻🄼🄽🄾🄿🅀🅁🅂🅃🅄🅅🅆🅇🅈🅉🅊🅋🅌🅍🅎🅏 🅐🅑🅒🅓🅔🅕🅖🅗🅘🅙🅚🅛🅜🅝🅞🅟🅠🅡🅢🅣🅤🅥🅦🅧🅨🅩🅪🅫🅬🅭🅮🅯🅰🅱🅲🅳🅴🅵🅶🅷🅸🅹🅺🅻🅼🅽🅾🅿🆀🆁🆂🆃🆄🆅🆆🆇🆈🆉 🆊🆋🆌🆍🆎🆏🆐🆑🆒🆓🆔🆕🆖🆗🆘🆙🆚
𪚹𪚺𪚻𪚼𪚽𪚾𪚿𪛀𪛁𪛂𪛃𪛄𪛅𪛆𪛇𪛈𪛉𪛊𪛋𪛌𪛍𪛎𪛏𪛐𪛑𪛒𪛓𪛔𪛕𪛖
MySQL 자료 형식을 utf8에서 utf8mb4으로 바꾸면 자료기지 용량이 조금 늘어나는 것은 어쩔 수 없다. utf8 → utf8mb4로 바꿀 때에는 자료 내용이 바뀌지 않지만, 거꾸로 utf8mb4 → utf8로 바꾸면 자료에 들어간 4바이트 문자들이 온전히 남지 않으니 주의해야 한다.
![미리보기 그림 - [텍스트큐브] 1.10.0의 이동 기기 화면에서 그림 제목을 제대로 보여 주려면](/image/4056_2.png)
![미리보기 그림 - [텍스트큐브] 라인(줄글)의 웹 주소 고리가 저절로 걸리게 하는 자바스크립트](/thumbnail/1/JP_Thumb/coverphoto/thumb_1979783447.png.webp)
![미리보기 그림 - [잡담] PHP 8.0으로 텍스트큐브 돌리기](/thumbnail/1/JP_Thumb/coverphoto/thumb_4619650063.png.webp)
![미리보기 그림 - [텍스트큐브] 설치 화면에서 "테이블을 생성하지 못했습니다"라고 나올 때](/thumbnail/1/JP_Thumb/coverphoto/thumb_1780738875.png.webp)
덧글을 달아 주세요