표준이 된 세벌식? - (3) 유니코드를 통한 요즘한글 부호계 표준화 작업
1) 어렵사리 개정된 유니코드 완성형 한글 부호계
유니코드 1.1에 들어간 완성형 한글 부호계는 아무리 너그럽고 견딜심 많은 프로그램 개발자라도 받아들이기 어려운 누더기 꼴이었다. 문자 부호값은 프로그램이 도는 기계가 처리하지만, 문자 부호값을 처리하는 프로그램을 만드는 것은 사람의 몫이다. 널리 쓰이는 문자 부호계가 다루기 까다로울수록 프로그램 개발자는 문자 입출력과 얽힌 기본 기능에 더 많은 시간과 정성을 쏟게 된다. 개발자의 어려움 때문에 프로그램이 더디 개발되거나 완성도가 떨어진다면, 소비자들도 알게 모르게 손해를 볼 수 있다.
생각하기에 따라서는 유니코드 1.1에 들어간 첫가끝 부호계(그림 11-13, 11-14)가 완성형 한글 부호계의 대안이 될 수도 있었으나, 1990년대 초반 무렵에 첫가끝 조합형은 프로그램 개발자들과 관련 전문가들에게 큰 관심을 끌지 못했다. 부호값 처리 방법과 글꼴 운용 방안의 내용이나 예제로 삼을 프로그램이 널리 알려지지 않았기 때문에,주1 프로그램 개발자들은 첫가끝 조합형이 무엇이고 왜 필요한지를 겪어서 깨닫기 어려웠다. N 바이트 조합형 등을 통하여 낱자 단위로 한글을 처리할 때의 번거로움을 겪어 본 것도 2바이트 조합형을 선호하는 프로그램 개발자들이 첫가끝 조합형을 다루기 꺼림직한 까닭이 될 수 있었다.
장래에 유니코드에 들어간 한글 부호계를 다룰 수 있는 처지였던 프로그램 개발자들은 한글을 낱내자 단위로 처리하는 완성형 부호계를 바라고 있었다. KS C 5601(지금의 KS X 1001)에 복수 표준으로 들어간 상용 조합형도 꼼꼼히 보면 KS 완성형처럼 낱내자 단위로 부호값을 붙이는 완성형 방식이다. 하지만 상용 조합형을 비롯한 2바이트 조합형은 KS 완성형과 달리 낱자들이 5비트 단위 부호값과 대응하므로, 낱내자 부호값을 알면 낱내자에 들어간 낱자 구성을 알 수 있다. 그래서 적지 않은 사람들이 2바이트 조합형과 같은 꼴을 완성형이 아닌 조합형으로 여기며 KS 완성형을 갈음할 대안으로 생각하고 지지했다. 유니코드를 제정하는 일에 참여한 국내 전문가들도 대체로 유니코드의 완성형 한글 부호계를 11172개 낱내자를 나타낼 수 있는 2바이트 조합형과 맞아떨어지는 꼴로 고치려고 힘을 기울였다.
아래는 국립 한글 박물관의 기획전 『디지털 세상의 새 이름_코드명 D55C AE00』에 공개된 기록 영상 "유니코드 영역 확보 전쟁"에 나오는 안대혁의 증언 내용 가운데 국제 표준 부호계인 유니코드에 한글 11172자가 가나다 차례로 들어가게 된 과정을 간추려 본 것이다.주2
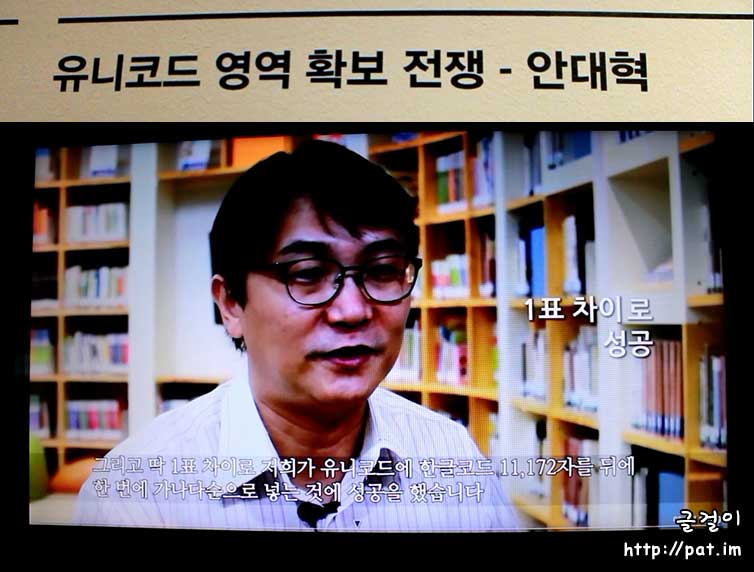

- 유니코드 협회 (Unicode Consortium)
- 유니코드의 판 구조
- 표준 유니코드에는 판(plane)이라고 부르는 문자판이 17개가 있음
- 첫번째 판은 65536개의 글자를 표헌할 수 있고, 그 뒤에 16개가 더 있음
- BMP(Basic Multilingual Plane)고 불리는 첫번째 판은 2바이트(16비트)로 문자를 표현함 (UCS-2)
- 그 뒤에 있는 100만자 글자들은 4바이트(32비트)로 문자를 표현함 (UCS-4)주5
- 두 바이트와 네 바이트의 차이 때문에 여러 나라들은 맨 앞에 있는 판(BMP)에 글자를 많이 넣고 싶어 함
- 첫번째 판에는 사용자 정의 문자 영역(PUA: Private Use Area)을 빼면 45000~46000자를 넣을 수 있음
(사용자 정의 문자 영역: 개인이나 회사가 특정한 목적으로 쓸 수 이는 영역)
- 표준 유니코드에는 판(plane)이라고 부르는 문자판이 17개가 있음
- 유니코드 1.0
- 첫번째 판의 45000자 영역에 각 나라의 표준들을 모아서 유니코드 1.0이 나옴
- 그 때에 한국은 완성형 한글 코드(KS 완성형 부호계)가 국가 표준 코드여서 유니코드 1.0에 현대 한글 11172자 가운데 2350자만 들어감
- 완성형 코드로 2350자밖에 표현을 못해서 조합형 코드 11172자로 현대 한글을 다 집어 넣자는 운동이 한창 벌어지던 와중에 국내 코드도 엉망이고 국제 표준 코드도 엉망이 되는 사태가 벌어짐
- 유니코드 1.1
- 1992년에 한국 국가 표준으로 11172자가 들어간 조합형 코드(2바이트 조합형 가운데 하나인 상용 조합형)가 국가 표준으로 완성형과 함께 들어갔지만, 조합형 코드가 유니코드에 반영되기는 굉장히 어려운 상황이었음
- 유니코드 1.1에 어쩔 수 없이 완성형 코드에 없었던 한글 낱내자들을 유니코드의 빈 영역에 몇 천자씩 몇 천자씩 해서 모두 6000자 정도를 집어 넣게 됨주6

- 마이크로소프트가 유니코드 협회에 한글 부호계를 제안함
- 1994년 봄쯤에 마이크로소프트는 윈도우 95을 개발하고 있었고, 마이크로소프트 한국 지사 이사 홍선기는 윈도우 95이 유니코드를 그대로 따르면 엉터리 한글 코드가 널리 쓰이는 것을 걱정함
- 홍선기는 기존 코드의 앞쪽에 있던 한글 글자(완성형 낱내자 6656개)들을 버리고 뒤쪽 빈 영역에 가나다 순으로 11172자를 넣자고 제안함
- 유니코드 협회는 물론이고 마이크로소프트 안에서도 받아들여지지 않음
- 홍선기(당시 마이크로소프트 한국지사 전무 이사)는 마이크로소프트 회장 빌 게이츠에게 "한글을 제대로 하기 위해서는 유니코드가 필요하니 마이크로소프트가 유니코드에 이 코드를 제안하게 해 달라"고 요청함
- 내부의 반대 의견을 무릅쓰고 마이크로소프트가 유니코드 협회에 코드(11172자가 가나다 차례로 들어간 완성형 한글 부호계)를 제안함
- 이 제안을 유니코드에 받아들일지를 유니코드 협회의 투표로 결정하게 됨
- 유니코드 협회에서의 표결
- 한글 11172자를 가나다 순으로 한꺼번에 넣으려면 기존 표준을 부정해야 하므로, 유니코드 협회장과 유니코드 협회에 참여한 여러 회사들의 반대에 부딪힘
- 유니코드 협회는 여러 회사가 모여 이룬 곳이어서 회사 하나가 투표권을 하나씩 가짐
- 투표 결과를 가늠해 보니 한 표가 모자람
- 만약 유니코드 협회에서의 표결에서 떨어지면 국제 표준화 기구(ISO)에 코드를 제안할 수 없음
- 그래서 1995년에 한글과컴퓨터에 근무하던 강태진과 함께 한글과컴퓨터 사장 이찬진을 졸라 유니코드 협회에 회비 10만 달러(약 1억 2000만 원)을 내고 가입하여 한 표를 더 투표함주7
- 1표 차이로 유니코드에 한글 코드 11172자를 가나다 순으로 넣는 것에 성공함주8
- 국제 표준화 기구에서의 표결
- 유니코드 협회가 만든 안은 국제 표준화 기구(ISO)에서 여러 나라 대표들이 참여하는 회의와 표결을 거치는 최종 승인을 받아야 국제 표준 코드가 될 수 있음
- 한글을 많이 집어넣을수록 한자를 넣을 공간이 줄어들므로, 한국이 11172자를 집어넣는 데에 중국과 일본이 가장 반대함
- 1995년에 로마 회의에서의 표결에서 한글 11172자가 가나다 차례로 들어간 코드가 1표 차이로 국제 표준 코드(유니코드 2.0)로 승인됨주9
- 유니코드 2.0이 제정된 뒤의 결과
- 인구도 많지 않고 영향력이 세지 않은 한국이 유니코드 첫째 판(BMP)의 1/4를 차지함
- 유니코드 첫째 판(BMP)에 한자는 약 2만 9000자만 들어가고, 14~15만 자에 이르는 나머지 한자들은 뒤의 문자판으로 밀림
- 1998년 무렵부터 만들어진 소프트웨어들이 거의 유니코드를 따르게 되었고, 오늘날에는 현대 한글 11172자가 들어간 유니코드를 쓰지 않는 기계나 장치가 거의 없게 됨
마이크로소프트는 1995년에 마이크로소프트는 11172개 낱내자가 가나다 차례로 담긴 완성형 부호계를 유니코드 기술 위원회(UTC: Unicode Technical Committee)에 제안하였다. 이 제안 내용이 컴퓨터 프로그램 개발 업체들이 참여하는 유니코드 협회에서 표결을 거쳐 승인되었고, 여러 나라 대표들이 참여하는 국제 표준화 기구(ISO)에서도 표결을 거쳐 승인되었다. 그렇게 하여 유니코드 2.0에서는 유니코드 1.1에 있었던 완성형 낱내자 6656개(2350 + 1930 + 6 + 2370)가 모두 빠졌고, 부호값 U+AC00 ~ U+D7A3 사이(가~힣)에 가나다 차례로 쭉 이어진 11172개 한글 완성자가 새로 들어갔다.
어떻게 보면 다른 나라 기업인 마이크로소프트가 한글 부호계에 관한 국제 표준 내용을 유니코드 협회에 제안한 것은 한국의 자존심이 다치는 일로 보일 수도 있다. 그렇지만 한국 지사를 두고 있는 마이크로소프트는 국내 프로그램 업계와 교류가 잦으면서 국제 무대에서의 영향력이 매우 큰 기업이다. 유니코드 2.0의 내용을 논의하기 시작한 때에는 아직 유니코드 협회에 가입한 국내 기업이 없었고, 다른 나라의 도움을 크게 바랄 수도 없었다. 유니코드의 완성형 한글 부호계를 고치는 일은 한자를 비롯한 다른 문자들을 더 넣으려는 다른 나라들의 이해와 부딪히므로, 이미 꼬인 결과물은 원만한 합의를 통하여 바로잡기 어려웠다. 그래서 유니코드 1.1에 한국 대표들이 바라는 꼴로 완성형 한글 부호계를 넣을 수 없었고, 도리어 더 일관성이 없는 꼴이 되고 말았다. 그런 때에 마이크로소프트가 나선 것이 유니코드의 완성형 한글 부호계를 고치려는 일에 실마리가 되어, 유니코드 개정 작업에 참여한 국내 전문가들은 표결을 통한 실현 가능성을 가늠하면서 실무 작업과 로비 활동에 집중할 수 있었다. 아직 틀을 잡아 가는 단계에 있던 유니코드가 장차 널리 쓰이는 데에도 마이크로소프트처럼 세계 시장을 주름잡는 기업의 협조가 필요했다. 그러므로 마이크로소프트가 제안한 한글 부호계가 유니코드에 들어간다면, 그 한글 부호계가 마이크로소프트가 개발하는 제품(특히 윈도우 운영체제)을 통하여 순탄하게 자리잡을 것이라고 점칠 수 있었다.
유니코드 2.0에 들어간 완성형 한글 부호계는 첫 · 가 · 끝 낱자를 나타내는 부호값이 따로 있지 않으므로 틀림없는 완성형 부호계이다. 하지만 11172개 완성자가 연속된 부호 공간에 가나다 차례로 쭉 이어져 들어가서, 2바이트 조합형보다도 조금 더 간단하게 낱자들을 낱내자(완성자)로 묶거나 낱내자를 낱자들로 풀 수 있다.주10 그러므로 완성형이면서도 조합형의 편의도 누릴 수 있게 절충된 꼴이다.
| 값 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 첫 | ᄀᅠ | ᄁᅠ | ᄂᅠ | ᄃᅠ | ᄄᅠ | ᄅᅠ | ᄆᅠ | ᄇᅠ | ᄈᅠ | ᄉᅠ | ᄊᅠ | ᄋᅠ | ᄌᅠ | ᄍᅠ | ᄎᅠ | ᄏᅠ | ᄐᅠ | ᄑᅠ | ᄒᅠ | |||||||||
| 가 | ᅟᅡ | ᅟᅢ | ᅟᅣ | ᅟᅤ | ᅟᅥ | ᅟᅦ | ᅟᅧ | ᅟᅨ | ᅟᅩ | ᅟᅪ | ᅟᅫ | ᅟᅬ | ᅟᅯ | ᅟᅮ | ᅟᅯ | ᅟᅰ | ᅟᅱ | ᅟᅲ | ᅟᅳ | ᅟᅴ | ᅟᅵ | |||||||
| 끝 | ᅟᅠᆨ | ᅟᅠᆪ | ᅟᅠᆩ | ᅟᅠᆫ | ᅟᅠᆬ | ᅟᅠᆭ | ᅟᅠᆮ | ᅟᅠᆯ | ᅟᅠᆰ | ᅟᅠᆱ | ᅟᅠᆲ | ᅟᅠᆳ | ᅟᅠᆴ | ᅟᅠᆵ | ᅟᅠᆶ | ᅟᅠᆷ | ᅟᅠᆸ | ᅟᅠᆹ | ᅟᅠᆺ | ᅟᅠᆻ | ᅟᅠᆼ | ᅟᅠᆽ | ᅟᅠᆾ | ᅟᅠᆿ | ᅟᅠᇀ | ᅟᅠᇁ | ᅟᅠᇂ |
한글 완성자 부호값 = 44032 + 첫소리값×588 + 가운뎃소리값×28 + 끝소리값
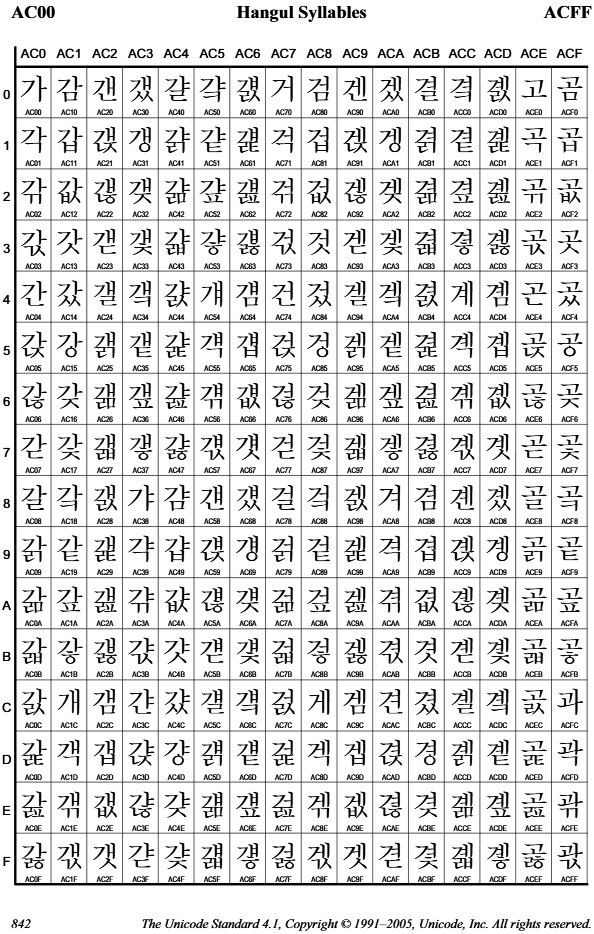
• 따온 곳 : The Unicode Standard, Version 4.1 Archived Code Charts (https://www.unicode.org/Public/4.1.0/charts/CodeCharts.pdf)
1980~1990년대에 쓰인 2바이트 조합형에서는 부호계의 종류마다 다른 3벌 낱자들의 5비트 부호값이 달랐고, 5비트 낱자 부호값들이 띄엄띄엄 있었다. 하지만 유니코드 2.0의 완성형 한글 부호계는 한글 낱내자가 쭉 이어진 부호계 공간에 들어가서 '가'의 부호값만 알면 나머지 낱내자들의 부호값들도 알아낼 수 있는 꼴이 되었다. 완성형 부호계이면서 2바이트 조합형 부호계의 편의를 더 크게 누릴 수 있는 셈이다.
차라리 KS 완성형이 나아 보일 만큼 엉망진창이었던 유니코드 1.1의 완성형 한글 부호계는 국내외 관계자들의 아낌없는 노력 · 협조 · 투자에 운까지 더해져서 한글을 다루는 사람들이 받아들일 수 있는 꼴로 바로잡힐 수 있었다. 그 과정에서 진통이 매우 컸다. 유니코드의 노른자위인 BMP 영역(U+0000 ~ U+FFFF)에 한글이 이미 들어간 문자들을 밀어내면서 11172자나 들어간 것은 다른 나라들의 반발을 부르고도 남는 일이었다. 국제 표준을 목표로 하는 부호계가 먼저 쓰이던 문자들의 부호값을 바꾸는 것은 표준으로서의 안정성을 해치는 일이기도 했다. 그런 무리수를 두면서까지 유니코드 2.0이 한국 대표들의 뜻대로 개정된 것은 아직 그 때에 유니코드가 거의 쓰이지 않았기에 가능한 일이었고, 마이크로소프트의 힘도 작용했다.
다만 이 일을 마지막으로 유니코드 2.0 이후에는 부호계에 한 번 올린 문자는 옮기거나 없애지 않는다는 정책이 세워졌다.주11 그래서 유니코드 2.0에 들어간 한글 11172자를 북조선에서 쓰는 낱자 차례로 바꾼다든지 하는 일은 할 수 없게 되었다. 그런 점에서 한국(남한)은 유니코드에서 작지 않은 특혜를 누린 셈이 되었다.
완성형이면서 2바이트 조합형과 호환되는 꼴로 바뀐 유니코드 2.0의 완성형 한글 부호계는 국내 표준인 KS C 5700에도 들어갔다.주12 유니코드를 개정한 효과가 1990년대 중반에 곧바로 나타나지는 않았지만, 2000년대에는 유니코드가 여러 운영체제들에 공통으로 쓰이는 국제 표준 문자 부호계로 차츰 자리잡았다. 이에 따라 유니코드 2.0부터 들어간 완성형 한글 부호계도 널리 쓰일 수 있는 기반 환경이 마련되었다.
한때 국내외 표준이 마구 꼬인 요즘한글 부호계 문제는 유니코드를 큰 폭으로 개정하는 우여곡절을 겪은 끝에 나은 쪽으로 풀리는 실마리가 잡혔다. KS 완성형으로는 나타내기 곤란했던 "어씃한 펲시맨과 거칢없는 똠방각하가 저깄던 찦차를 쓔웅쓩 타던 모습이 섬찟하더라"는 문장은 유니코드 2.0에 들어간 한글 부호계로는 잘 나타낼 수 있다. 손글씨나 기계식 타자기로 나타낼 수 있는 글을 비로소 컴퓨터로도 널리 나타낼 수 있는 토대가 마련된 셈이다. 세월이 흐를수록 유니코드를 지원하는 새 프로그램들이 자리잡으면서 KS 완성형이 일으키던 불편은 사라지고 있다.
그러나 아직도 KS 완성형 부호계가 쓰이던 때의 제약이 다 사라지지는 않았다. 2018년에 청와대의 국민청원 게시판에는 각종 증명서에 '설믜'라는 이름을 제대로 올릴 수 없어서 금융 상품과 전화 회선 가입이 어려웠고 의료보험, 국가장학금, 월급을 쉽게 받지 못한 '김설믜'의 호소문이 올라 왔다. 이를 보도한 언론사마저 기사에 들어가는 '믜'를 나타내지 못하여 소동이 벌어지기도 하였다.주13 이처럼 유니코드가 널리 쓰이는 시대가 됐는데도 KS 완성형이 쓰이던 때의 한글 처리 방식에 머물러 있는 프로그램들 때문에 몇몇 사람들이 지난날의 불편을 그대로 겪는 사례가 아직도 있다.
2) 유니코드 완성형 한글 부호계의 한계
유니코드 2.0에 들어간 완성형 한글 부호계는 KS 완성형보다 2바이트 조합형과 더 잘 들어맞는 꼴이다. 그래서 1990년대 중반 무렵에 한글 부호계 문제에 관심을 둔 사람이라면 거의 누구나 환영할 수 있는 꼴이었다. 그러나 이 한글 부호계는 완성형이라는 굴레 때문에 모든 유형의 한글을 나타내지는 못하는 약점을 안고 있다.
유니코드 2.0에 들어간 완성형 한글 부호계는 한글을 나타내는 폭이 2바이트 조합형 부호계보다 좁다. 전상훈은 《마이크로소프트웨어》에 기고한 기사에서 유니코드 2.0의 완성형 부호계(유니완성형)로 2바이트 조합형에서 채움값을 써서 나타내던 미완성 낱내자(미완성 음절 문자)를 나타낼 수 없음을 꼬집어 이야기하였다.
먼저 유니완성형 영역에서 처리하는 현대어 음절 11,172자에 문제가 있다. 정확히 말해 현대어 음절은 11,172자가 아니라 12,319자이다. 이렇게 차이가 나는 것은 미완성 음절 문자 1,147자가 있기 때문이다. 이것은 과거 KS완성형과 대립하는 과정에서 조합형에서 사용하는 완성된 음절을 이루는 글자가 11,172자로 보았기 때문에 차이가 발생했다. 미완성 음절 문자는 ‘초성:채움:채움(ㄱ), 채움:중성:채움(ㅏ), 채움:채움:종성(ㅆ), 채움:중성:종성( ), 초성:채움:종성’등의 글자 형태를 말한다. 이러한 글자들이 현대어에서 빠지게 되면서 옛한글처럼 유니조합형에서만 처리할 수 있도록 배정되는데, 이로 인해 앞으로(1995년 3월 이후) 개발될 운영체제에서는 현대어를 11,172자만을 처리하게끔 정해지게 되었다.
이렇게 된 근본적인 원인을 살펴보면, 유니코드 2.0이 제정되기 전까지 KS 완성형과의 논쟁에 집착한 나머지 조합형에서 현대어 음절이 정확하게 몇 자인지 모르고 있었다는 것이 가장 큰 문제였다. 실로 어처구니 없는 일이지만 이미 ‘엎질러진 물’처럼 엄연한 현대어이면서 옛한글을 처리하기 위해서 만들어 놓은 유니조합형 영역에서 함께 처리되는 결과를 낳게 되었다. 게다가 이러한 잘못된 판단으로 유니조합형에서는 현대어 자모와 옛한글 자모가 뒤엉키게 되어 정렬이나 탐색에서 심각한 문제를 불러 일으킨다.
전상훈, 「민족 문화의 정수, 한글을 한글답게! ― 펩시맨과 똠방각하가 찦차를 탄 이유는…」, 《마이크로소프트웨어》, 1998.11.
2바이트 조합형에서는 그 자리에 낱자가 비었음을 나타내는 채움값을 써서
- 첫소리 채움 + ㅏ + 끝소리 ㄴ → ᅟᅡᆫ
- 첫소리 ㄱ + 가운뎃소리 채움 + 끝소리 ㄴ → ᄀᅠᆫ
처럼 낱자를 제대로 갖추지 못한 미완성 한글을 나타낼 수 있었다. 그러나 낱자를 제대로 갖춘 낱내 완성자 11172개만 들어간 유니코드 2.0의 완성형 부호계로는 미완성 한글을 나타낼 수 없다. 미완성 한글은 위의 글에서 '유니조합형'으로 이야기된 '첫가끝 조합형'으로 나타낼 수 있다.
문자 부호계와 문자 입출력 처리 프로그램을 고친다면, 유니코드에 1147자를 더 넣어서 2바이트 조합형처럼 미완성 한글까지 완성형으로 다루게 하는 일은 어렵지 않다. 하지만 실제로 그렇게 하기에는 다른 쪽에서 형평 문제와 일관성 문제가 걸린다. 오늘날에 자주 쓰이고 있는 문자들이 주로 들어가는 유니코드의 BMP 영역은 많아야 65536개 부호값을 쓸 수 있는데, 이 한정된 공간에서 1147개는 적지 않는 수이다. 이미 11000개가 넘는 부호값을 차지하고 있는 한글이 더 많은 부호값을 차지할수록 다른 문자를 넣을 공간이 줄어든다. 미완성 한글처럼 실제로 필요해서 쓰이는 때보다 오타 같은 예외 상황에서 더 자주 나올 수 있는 문자들을 넣느니, 'ᄒᆞᆫ'처럼 아래아(ㆍ)가 들어가는 낱내자들을 넣는 것이 더 실속 있을 수도 있다.
한글이나 한말을 분석하는 글에서는 낱자를 따로 나타내는 때가 더러 있다. 유니코드에서는 호환용 한글 자모로도 낱자를 나타낼 수 있지만, 호환용 한글 자모는 첫닿소리와 끝닿소리(받침)가 나뉘지 않은 2벌식 체계이다. 그래서 호환용 한글 자모로는 2바이트 조합형을 쓰던 때처럼 'ᄂᅠ'과 'ᅟᅠᆫ'을 첫닿소리와 끝닿받침를 가려 나타낼 수 없어서, '첫소리 ㄴ'과 '끝소리 ㄴ'으로 나타내곤 한다.
옛한글에서는 ㅿ · ㆁ · ꥼᅠ · ㅵ · ㆉ처럼 요즘한글에는 쓰이지 않는 낱자들이 쓰인다. 전산 기기로 나타낼 한글의 폭을 요즘한글에만 한정하지 않고 옛한글까지 넓히려면, 이미 유니코드 1.1부터 들어간 첫가끝 부호계를 쓰는 것 말고는 달리 대안이 없다.하지만 일찍부터 한글 부호계 문제에 관심을 두었던 전문가들도 재빨리 첫가끝 조합형으로 관심을 돌리기는 쉽지 않았다. 1990년대에는 옛한글을 담은 문헌 조사가 끝나지 않았고, 옛한글까지 나타낼 첫가끝 조합형의 부호값 운용 방안이 확정되었다고 보기 어려웠다. 그 무렵에 2바이트 조합형으로도 일반인들의 수요를 따라갈 수 있었던 프로그램 개발사들로서는 나중에 부호계나 운용 방안이 바뀔 수도 있는 첫가끝 조합형에 서둘러 매달릴 까닭이 없었다.
그러나 미완성 한글과 옛한글도 틀림없는 한글의 영역이다. 흔히 '옛한글'로 불리는 한글 유형은 옛 우리말을 나타낼 때 많이 쓰이지만, 요즈음 쓰이는 사투리를 적는 데에도 쓰인다. 그래서 옛한글이 꼭 옛말이나 옛글을 연구하는 사람들에게만 필요한 것은 아니다. '믜'나 '똠'이 드물게 쓰이고 KS 완성형으로 나타내지 못한다고 하여 포기할 한글이 아닌 것처럼, 'ꥼᆡᇖ'이나 'ᅟᅡᆫ' 같은 한글도 당장 유니코드 완성형 부호계로 나타내지 못한다고 하여 영영 내버려 둘 수는 없었다. 그래서 관련 전문가들은 유니코드 완성형 부호계를 어렵사리 고치고 난 뒤에도 미완성 한글과 옛한글을 처리하지 못하는 빈틈을 메우고자 다시 머리를 맞대고 방법을 찾아야 했다.
▣ 마이크로소프트의 확장 완성형 (CP949)
1994년 말에 마이크로소프트(Microsoft)는 나중에 시장에 내놓을 윈도우 95에서 조합형(2바이트 조합형)을 운영체제 차원에서 지원할 뜻을 밝힌 적이 있었다. 1995년에는 앞에서 본 것처럼 마이크로소프트가 유니코드 기술위원회에 제안하여 유니코드 2.0에 가나다 차례로 정렬된 완성형 한글 부호계가 들어가게 하는 계기를 마련하였다. 그러므로 새로 나올 마이크로소프트의 윈도우 제품에는 2바이트 조합형처럼 가나다 차례로 차례짓기를 하기 좋은 한글 부호계가 쓰일 것이라고 기대할 수 있었다.
그런데 1995년 5월에 마이크로소프트는 입장을 바꾸어 윈도우 95 한글판에 '한글 통합형' 또는 '확장 완성형'이라고 불리는 완성형 한글 부호계를 넣겠다는 뜻을 밝혔다. 나중에 확장 완성형으로 흔히 불리게 된 이 완성형 한글 부호계는 UHC(통합형 한글 코드, Unified Hangul Code), CP949(코드 페이지 949, Code Page 949)으로도 불리고 있다.주14

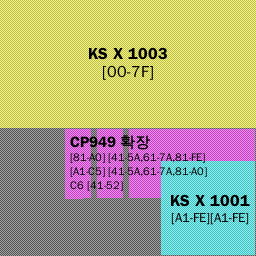
마이크로소프트의 확장 완성형은 KS C 5601(KS X 1001)에 정의된 KS 완성형 부호계가 들어간 EUC-KR에 한글 낱내 완성자 8822개를 끼워 넣은 확장판이다. 2바이트 체계인 KS 완성형 부호계를 그대로 쓰면서 KS 완성형에서 나타내지 못한 '똠, 펲, 얬' 등을 나타낼 수 있게 하는 것을 목적으로 한 부호계이다. 2바이트 조합형에서 나타낼 수 있는 미완성 낱내자 1147개는 나타내지 못하지만, 유니코드 2.0에 들어간 11172개 완성형 낱내자들은 모두 확장 완성형으로 나타낼 수 있다.
| 첫째 바이트 | 두째 바이트 | 나타내는 문자 | 비고 |
|---|---|---|---|
| 0x00 ~ 0x7F | 없음 | 7비트 아스키 영역 숫자, 기호, 영문 로마자 |
= KS X 1003 |
| 0xA1 ~ 0xFE | 0xA1 ~ 0xFE | KS 완성형 한글 2350자 |
2350자끼리 가나다 차례 (= KS X 1001) |
| 0x81 ~ 0xA0 | 0x41 ~ 0x5A 0x61 ~ 0x7A 0x81 ~ 0xFE |
확장 완성형 한글 8822자 |
8822자끼리 가나다 차례 |
| 0xA1 ~ 0xC5 | 0x41 ~ 0x5A 0x61 ~ 0x7A 0x81 ~ 0xA0 |
||
| 0xC6 | 0x41 ~ 0x52 | ||
| 0xCA ~ 0xFD | 0xA1 ~ 0xFE | KS 완성형 한자 4888자 |
= KS X 1001 |
유니코드 2.0에 들어갈 완성형 한글 부호계의 내용이 확정되면서 잦아들 것 같았던 한글 부호계 논쟁은 마이크로소프트가 KS 완성형을 확장한 완성형 한글 부호계를 또 내놓으면서 다시 불이 붙었다. 이 확장 완성형이 비판 받은 까닭은 유니코드 1.1의 완성형 한글 부호계와 비슷했다. 확장 완성형의 한글 낱내자 부호값들은 낱자 차례가 따로 정렬된 두 뭉치로 나뉘어 있으므로, 한글 정보를 처리할 때에 KS 완성형보다 더 큰 변환표가 필요하다. 부호값에 바탕한 한글 정보 처리가 KS 완성형보다 번거로워지므로, 마이크로소프트가 확장 완성형의 내용을 밝히자마자 반발하는 여론이 빗발쳤다.
문서 편집기(워드프로세서) 시장에서 마이크로소프트의 제품(MS 워드)과 경쟁하던 한글과컴퓨터의 'ᄒᆞᆫ글'은 2바이트 조합형인 상용 조합형(KSSM)에 옛낱자를 끼워 넣은 '한컴 2바이트 조합형'을 쓰고 있었다. 한글과컴퓨터는 1995년 6월에 한컴 2바이트 조합형을 '확장 조합형'으로 일컬으며 확장 조합형으로 마이크로소프트에 맞설 뜻을 밝혔다.주15 주16 한글윈도우 95 발표회가 열린 1995년 11월에는 마이크로소프트의 확장 완성형에 반대하는 이들이 삼성역 아케이드 광장에 모여 성명서를 발표하며 반대 집회를 열기도 하였다. 확장 완성형에 얽힌 논란이 커지자 공업진흥청은 유니코드 2.0에 들어간 완성형 한글 부호계의 내용을 12월 7일에 국내 표준 규격(KS C 5700)으로 제정하여 마이크로소프트에 반발하는 여론에 힘을 실었다.주17 이에 마이크로소프트는 한 발 물러나서 윈도우 95 제품에서는 확장 완성형을 기본으로 쓰지 않았고, 윈도우 98부터 확장 완성형을 기본으로 쓰기 시작했다.
확장 완성형은 나라 또는 국제 기구가 공인한 표준 방식이 아니었지만, 마이크로소프트 윈도우의 영향력을 등에 업고 윈도우와 인터넷(웹, 전자우편, 텔넷 등)에서 흔히 쓰였다. 지난 글(https://pat.im/1150)에서 본 KS C 5657(정보 교환용 부호 확장 세트, KS X 1002)은 8822자 가운데 일부인 1930자만 규정한 데다가 외국 문자도 아닌 한글을 조합하는 때에 이스케이프 시퀀스 방식을 써야 하는 번거로움이 있어서 표준이었음에도 전혀 쓰이지 못했다. 통신 매체들에 널리 쓰이던 KS 완성형 부호계와 호환되면서 8822개 한글 낱내자를 더 나타낼 수 있는 방안이 마땅한 게 없었기 때문에, 확장 완성형은 유니코드가 널리 쓰이기 앞서 임시로 쓸 수 있는 요즘한글 표현 방안이 되었다.
마이크로소프트의 확장 완성형은 아직 유니코드를 널리 쓸 수 없던 때에 KS 완성형으로 나타내지 못하던 한글(똠, 펲 등)을 나타낼 길을 트는 구실을 했지만, 문제점도 있었다. 확장 완성형은 표준 부호계를 EUC-KR의 비표준 확장판이다. 업계에 미치는 마이크로소프트의 영향력 때문에 한글을 다루는 프로그램들 사이에서는 겉으로는 EUC-KR을 한글 부호 매김 방식으로 내걸면서도 속으로는 확장 완성형(CP949, UHC)까지 처리하는 것이 업계 관행처럼 통하는 때가 많았다. 하지만 EUC-KR 규격에서 확장 완성형은 표준에 근거를 둔 규격이 아니므로, EUC-KR을 쓰는 프로그램들이 꼭 확장 완성형을 지원할 의무는 없다. 그래서 똠, 펲, 믜처럼 KS 완성형으로는 나타내지 못하는 낱내자들은 EUC-KR이 쓰이는 환경에서 어떤 프로그램에서는 잘 처리되고 어떤 프로그램에서는 잘 처리되지 않기도 하는 불안정한 상태에 놓일 수 있었다.
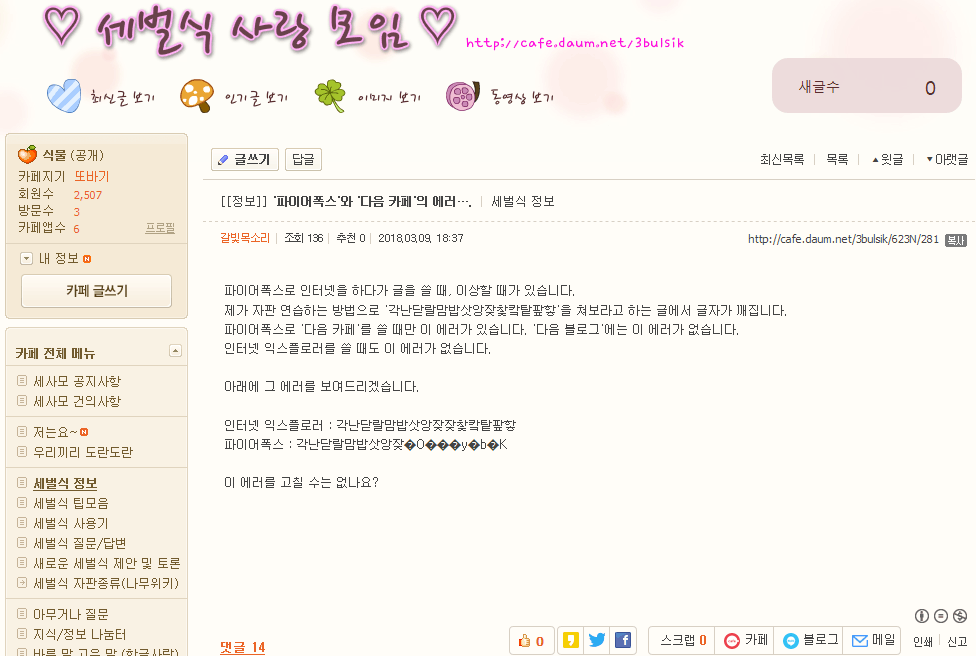
이 때문에 몇몇 프로그램들에서 KS 완성형에 없는 한글 낱내자가 오갈 때에 문제를 빚을 수 있었다. 이를테면 다음 카페(cafe.daum.net)는 2018년 초까지 EUC-KR이 쓰였는데, 웹 누비개(웹 브라우저) 가운데 하나인 파이어폭스(Firefox)로 글을 쓰면 KS 완성형으로 나타내지 못하는 낱내자가 잘 처리되지 않고 깨져 나오는 문제가 일어났다. 그래서 '각난닫랄맘밥삿앙잦찿캌탙팦핳'을 쳐서 타자 연습을 하는 '세벌식 사랑 모임'의 회원(갈빛목소리)이 파이어폭스로 다음 카페에 글을 올릴 때에 '찿캌탙팦핳'이 잘 들어가지 않고 깨지는 일을 겪기도 하였다.
- '파이어폭스'와 '다음 카페'의 에러…. (http://cafe.daum.net/3bulsik/623N/281)
이 문제는 부호 매김 방식을 EUC-KR로 지정했을 때에 다른 프로그램들이 확장 완성형으로 처리해 주던 비표준 관행을 파이어폭스(Firefox)가 따르지 않아서 생긴 문제이다. 다음 카페의 부호 매김 방식이 UTF-8로 바뀐 뒤에는 파이어폭스로 다음 카페에서 '찿캌탙팦핳'를 넣을 때에 글이 깨지는 문제가 사라졌다.
- 파이어폭스와 다음 카페의 에러가 고쳐졌군요. ^^ (http://cafe.daum.net/3bulsik/623N/283)
- 다음 카페 한글 인코딩 방식이 유니코드(UTF-8)로 바뀌었습니다. (http://cafe.daum.net/3bulsik/623N/284)
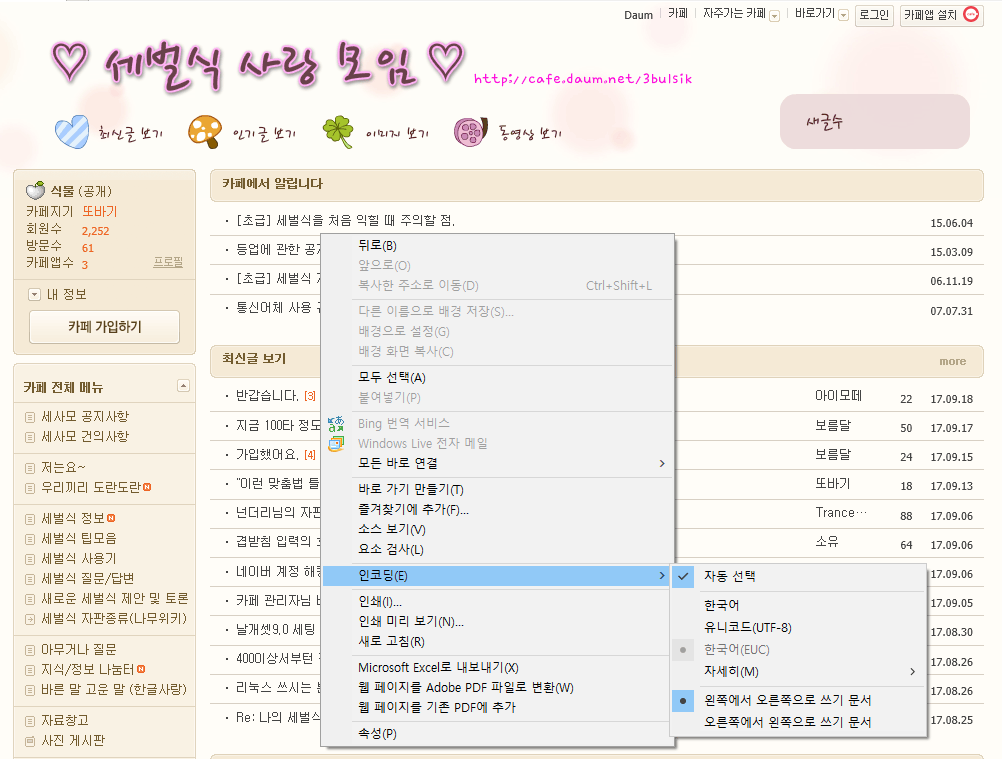

아래아 마을(http://cafe.daum.net/jejuarea)은 요즘 사투리인 제주말을 많이 다루는 곳이다. 아래아(ㆍ)가 자주 들어가는 제주말은 유니코드와 첫가끝 조합형을 다룰 수 있는 UTF-8로 나타낼 수 있고, EUC-KR에 쓰이는 부호값으로는 바로 나타내지 못한다. EUC-KR이 쓰이던 때의 다음 카페에서 제주말이 담긴 글을 나타내려면, 아래아가 들어간 낱내자를 다음처럼 첫가끝 낱자들의 부호값이 들어가는 HTML 문자 참조형으로 바꾸어 넣어야 했다.
- ᄒᆞ : ᄒᆞ
- ᄒᆞᆫ : ᄒᆞᆫ
- 미안ᄒᆞ우다 : 미안ᄒᆞ우다
그래서 아래아 마을에서는 글에서 아래아가 든 낱내자들을 위와 같이 HTML 문자 참조형으로 바꾸어 주는 프로그램인 '아래아 입력기'(http://cafe.daum.net/jejuarea/WyNv/22)도 쓰여 왔다. 이제는 다음 카페가 UTF-8을 지원하게 된 덕분에 아래아가 들어간 낱내자를 꼭 HTML 문자 참조형으로 바꾸어 넣어야 할 필요는 사라졌다. 그러나 다음 카페가 옛한글을 나타내지 못하는 '굴림'체를 기본으로 쓰고 있어서, 글꼴을 따로 지정할 수 없는 덧글은 윈도우 환경에서 아래아가 들어가는 글의 낱자들이 풀려 나오는 문제가 남아 있다.
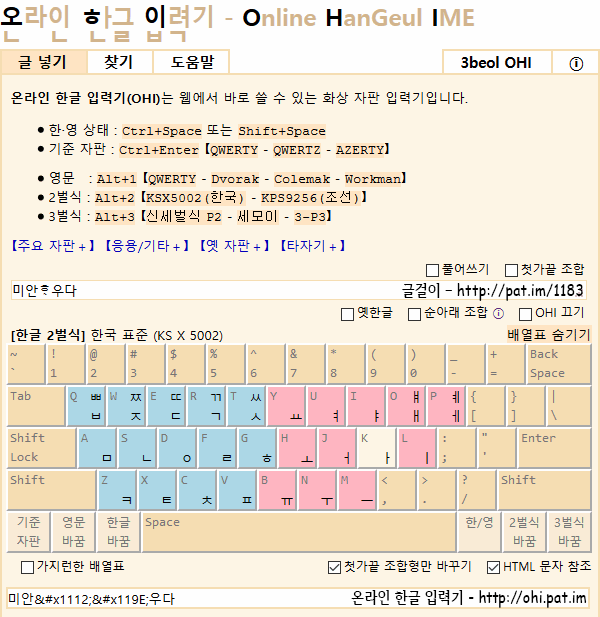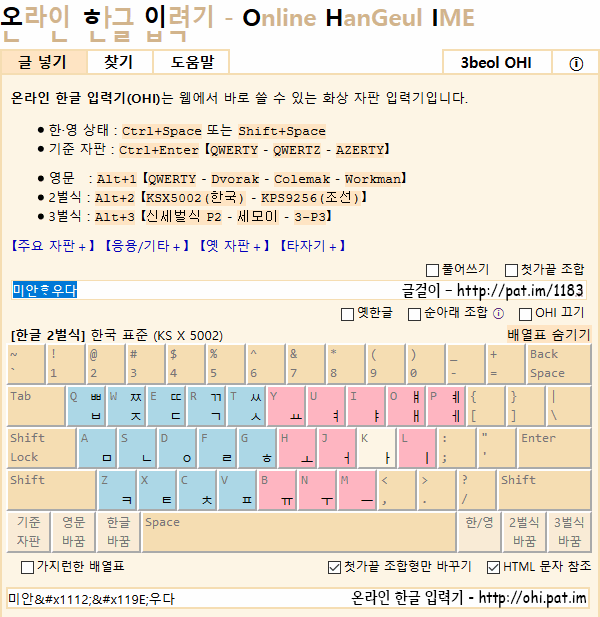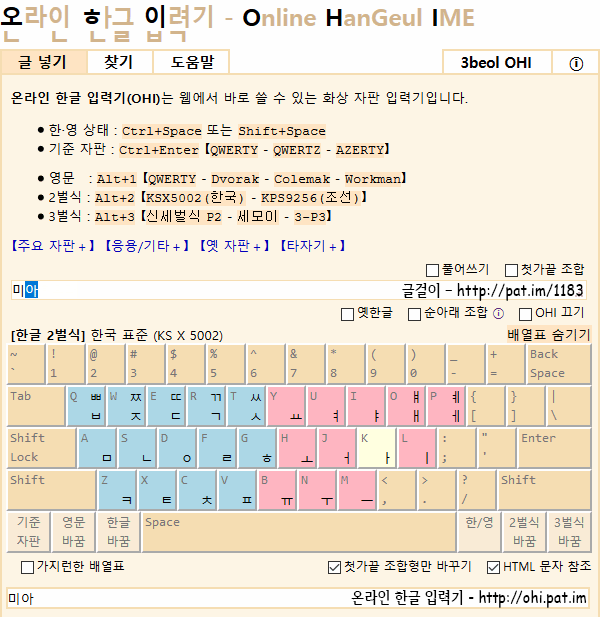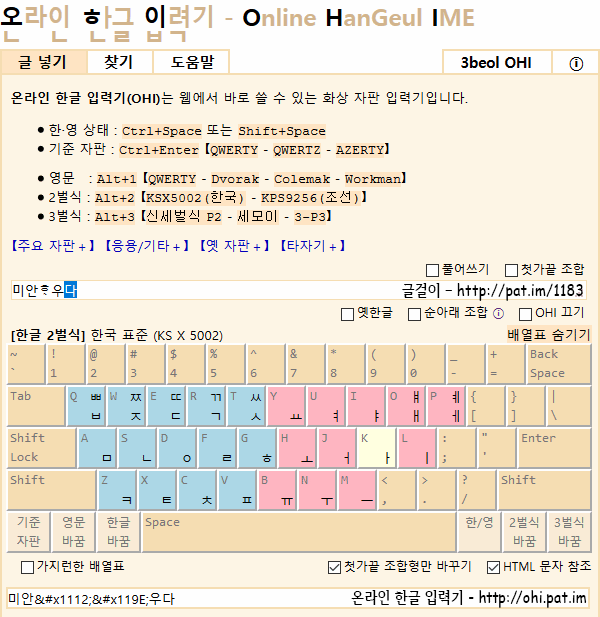
온라인 한글 입력기 : http://ohi.pat.im/?ko=2-KSX5002
(2019.7.3. 그림 12-10을 더하여 넣음)
확장 완성형은 유니코드가 널리 쓰이지 못하는 때에 임시로 쓰려고 만든 한글 표현 방안이었으므로, 처음 나온 때부터 언젠가 사라질 운명이 지워져 있었다. 요즈음에는 윈도우 운영체제 등에서 프로그램으로 주고받는 글들을 알아서 유니코드로 바꾸어 주므로, KS 완성형이나 확장 완성형으로 기록된 파일 내용을 꺼내더라도 따로 변환 작업을 할 필요는 느끼지 못할 수 있다.
만약 EUC-KR이 KS 완성형 그대로 2350개 낱내자만 나타낼 수 있게 쓰였다면, 한글을 나타낼 수 있는 폭이 제한되는 불편 때문에 웹 문서를 UTF-8로 바꾸려는 움직임이 더 빨랐을 수도 있다. 그러나 확장 완성형(CP949)을 쓰면 EUC-KR로도 11172자를 모두 나타낼 수 있어서 웹 개발자 및 운영자와 일반 사용자가 UTF-8로 얼른 갈아탈 필요를 덜 느낄 수 있었다. 그렇다 보니 확장 완성형은 다음 카페가 그랬던 것처럼 한글이 담긴 웹 문서들의 부호 매김 방식이 EUC-KR에 더 오래 머무르게 한 면이 있다.
지난날에는 다른 나라들에서도 EUC-JP나 GB2312처럼 문화권마다 다른 문자 부호 매김 방식들이 다양하게 쓰여서, 부호 매김 방식을 잘못 지정하거나 프로그램이 잘못 알아차리면 글이 깨진 모습으로 보일 수 있었다. 그래서 지난날의 웹 누비개(웹 브라우저)들에서는 그림 12-8과 12-9에 보이는 부호 매김 방식을 지정하는 차림표가 눈에 잘 띄거나 쉽게 부를 수 있는 곳에 있었다. 하지만 2000년대 이후에 인터넷에서 쓰이는 부호 매김 방식이 점차 유니코드를 쓰는 UTF-8으로 통합되고 있고, 2010년대 후반인 요즈음에는 UTF-8을 따르지 않는 그물집이 흔하지 않다. 그래서 요즈음의 웹 누비개들은 부호 매김 방식을 고르는 차림표를 찾기 어려운 곳에 두거나 아예 없애는 추세에 있다.참고한 자료
- 신기섭, 「새 한글코드 '확장 완성형' 등장」주18, 《한겨레신문》, 1995.5.23.
- 「한글과컴퓨터 "확장조합형" 고수」, MK뉴스(매일경제), 1995.6.5. (http://news.mk.co.kr/newsRead.php?sc=30000001&year=1995&no=24773)
- 신기섭, 「한글코드 싸움 ‘제2 라운드’ ― 마이크로소프트 “완성형” 한글과 컴퓨터 “조합형” 고수 선언」, 《한겨레신문》, 1995.6.6.
- 양왕성, 「유니코드와 한글 통합형 코드」, 정보시대, 《마이크로소프트웨어》, 1995.7.
- 이승현, 「MS의 한글코드, 상업적 접근 곤란」, 컴퓨터사, 《컴퓨터》, 1995.7.
- 이정환, 「한글통합형 코드, 누구를 위한 선택인가」, 두성정보통신, 《PC 서울》, 1995.7.
- 정의식, 「다시 시작된 조합형, 완성형 한글 코드 논쟁 ― 확장 완성형이란?」, 민컴, 《마이컴》, 1995.7.
- 신기섭, 「MS사 야심에 한글표준코드 ‘휘청’」, 《한겨레신문》, 1995.9.12.
- 신기섭, 「한글표준과 윈도스95 코드 어떻게 다른가」, 《한겨레신문》, 1995.9.12.
- 이승현, 「「한글 윈 95」…통합형 후퇴 완성형 회귀 ― 「유니코드」 전환 때 또 혼란 가능성」, 컴퓨터사, 《컴퓨터》, 1995.10.
- 「공진청, 한글 코드 국제 규격 확정 ― 1만1,172자 사전식 배열 완성형으로」, 컴퓨터사, 《컴퓨터》, 1995.10.
- 김학진, 「「윈도95」도 새 체계 수용 ― 공진청 한글코드확정 해설」, 《동아일보》, 1995.12.8.
- 길윤웅 · 나상인, 「확장완성형코드, 시대유감」, 한글과컴퓨터, 《한글과컴퓨터》, 1996.1.
- 강태진, 「나는 컴퓨터 독립 운동가」, 현암사, 〈세상은 꿈꾸는 자의 것이다〉, 1996.3.
- 전상훈, 「민족 문화의 정수, 한글을 한글답게! ― 펩시맨과 똠방각하가 찦차를 탄 이유는…」, 정보시대, 《마이크로소프트웨어》, 1998.11.
- 김경석, 〈컴퓨터 속의 한글 이야기 둘째 보따리〉, 부산대학교 출판부, 1999.12.31. (23째 쪽 KS X 1005-1에 관한 설명)주19
- 안대혁, "유니코드 영역 확보 전쟁"(영상 자료), 국립한글박물관 기획전 『디지털 세상의 새 이름_코드명 D55C AE00』, 2015.10.6. ~ 2016.1.31.
- 위키백과
- 국제 문자 세트 : https://ko.wikipedia.org/wiki/국제_문자_세트
- EUC-KR : https://ko.wikipedia.org/wiki/EUC-KR
- 코드 페이지 949 : https://ko.wikipedia.org/wiki/코드_페이지_949
- 문자 집합 위키
- 세벌식 사랑 모임
- 갈빛목소리, 「'파이어폭스'와 '다음 카페'의 에러….」, 2018.3.9., http://cafe.daum.net/3bulsik/623N/281
- 갈빛목소리, 「파이어폭스와 다음 카페의 에러가 고쳐졌군요. ^^」, 2018.4.8., http://cafe.daum.net/3bulsik/623N/283
- 팥알, 「다음 카페 한글 인코딩 방식이 유니코드(UTF-8)로 바뀌었습니다.」, 2018.4.16., http://cafe.daum.net/3bulsik/623N/284






덧글을 달아 주세요
전마머꼬 2020/02/04 15:44 고유주소 고치기 답하기
iconv를 다루다보니... cp949 euc-kr을 자판으로 써본적은 있는데...
어떻게 다른지를 몰랐는데 알게되어 기쁩니다.
한글독립이 어쩌네 하면서 마이크로소프트에 한컴이 안넘어가게 온 국민이 도와주었던 것 같은데...
한글독립은 한국마이크로소프트가 이루었네요...
뭔가 대한민국독립도 그렇고 한글독립도 그렇고, 보조는 해주는데 주도적으로 이루지 못하고.
미국에 도움을 얻었군요... 굉장히 아이러니합니다.
블로그글 엮어서 종이책으로 출간하시면 좋겠어요. 배움도 있으면서 즐거움도 있네요.
전마머꼬 2020/02/04 15:47 고유주소 고치기 답하기
확장영역은 정렬에 있어서 문제를 겪을 수 밖에 어ㅄ(shift.....chrome)어서
책 뒤에 사용된 단어 정렬하는데 저 영역 글자가 들어가면 출판사 직원지 수작업을 해야할 것 같은데
아이구...
팥알 2020/02/04 16:56 고유주소 고치기 답하기
문서 작업할 때는 ᄒᆞᆫ글(아래아한글)을 주로 써 오다 보니 다른 프로그램들에서 겪을 수 있는 정렬 문제를 깊이 생각해 본 때가 많지 않았네요. 요즘 쓰이는 한글 부호계에도 아쉬움은 있지만, 결과가 더 나빴다면 어땠을까 하는 아찔함도 있습니다.
어쩌면 마이크로소프트가 굳게 마음만 먹었으면, 한글 문화권 전체를 궁지에 몰 수도 있었습니다. 유니코드 문제에서 한국 쪽에 유리하게 협조해 줘야 할 의무가 없는데 막강한 힘을 보탠 바 있고, 한컴 사태 때 계약을 지키라고 요구하는 게 생떼는 아닌데 그러지 않았습니다. 그렇게 하는 게 기업 입장에서 길게 보면 유리하다는 판단을 했을 수도 있지만, 저는 당시 빌 게이츠 회장을 비롯한 마이크로소프트의 결정권 있는 분들의 양심과 철학이 어느 만큼은 작용했을 것이라고 생각합니다.
차라리 유니코드 완성형이 좌절되고 요즘한글까지 유니코드 조합형(첫가끝 조합형)으로 나타내는 길을 걸었으면 좋았겠다는 생각도 해 봅니다. 그랬으면 BMP 영역에서 한글이 차지한 11172개나 되는 부호값을 꽤 많이 아낄 수 있었겠죠. 하지만 세상이 정말 뜻하는 대로만 돌아갈 수는 없겠죠. 2바이트 방식을 쓰던 때에 갑자기 첫가끝 조합형을 쓰려 했다면 큰 혼란이 있었을 것이고, 아직도 국내에서 첫가끝 조합형을 주로 쓰는 데에는 어려움이나 번거로움이 있는 게 현실이니까요.
ㅇㅇ 2022/02/24 22:59 고유주소 고치기 답하기
저도 유니코드 조합형이 채택 됐다면 어땠을까 하는 아쉬움은 있습니다.
한글이 2020/10/11 04:27 고유주소 고치기 답하기
좋은 글 잘 읽고갑니다^^